



 Рейтинг: 4.6/5.0 (1863 проголосовавших)
Рейтинг: 4.6/5.0 (1863 проголосовавших)Категория: iOS: Бенчмарки, тесты
Этот материал предназначен, прежде всего, тем, кто в своей работе использует или собирается использовать кластерные системы. В работе рассматривается процесс тестирования кластеров при помощи специальных наборов тестов. Уделено внимание всем уровням рассматриваемого вопроса, начиная от общих методологических аспектов и заканчивая практическими рекомендациями настройки тестовых пакетов.
Берутся во внимание кластерные системы, ориентированные преимущественно на научные исследования (science workload) и численные расчеты.
Статья не затрагивает общие вопросы построения кластерных систем и организации параллельных вычислений.
Статья написана в надежде, что поможет специалистам и интересующимся лицам ответить на, возможно, неизвестные им вопросы в области тестирования кластерных систем.
Перед прочтением рекомендую обратить внимание на терминологию и общие вопросы кластеринга.
В рамках работы под кластерной системой (кластером) будем понимать массивно-параллельную систему, состоящую из одинаковых узлов — гомогенная среда. Каждый узел обязательно имеет центральный процессор (или несколько), локальную оперативную память (без возможности прямого доступа к оперативной памяти других узлов), коммуникационное устройство. Все узлы системы связаны посредством некоторой коммуникационной среды (FastEthernet. Myrinet. GigabitEthernet, Scalable Coherent Interface — SCI) и образуют локальную вычислительную сеть (ЛВС). В ЛВС действует среда передачи информации между узлами. Эта среда предоставляет приложениям пользователя интерфейс к своим функциям, реализованным посредством взаимодействия с операционной системой.
Частным случаем такой системы является вычислительная ферма — кластер, все узлы которого размещены в одном корпусе.
Необходимо отметить, что рассматриваемое в статье программное обеспечение нацелено на использование в UNIX подобных операционных системах, которые являются наиболее распространенными в мире кластеров.
… и зачем?Тестирование кластеров необходимо проводить по многим объективным причинам. На мой взгляд, основной причиной для тестирования должно быть естественное желание увеличить вычислительную мощность системы. Немаловажной задачей также является определение различных факторов, прямо или косвенно сказывающихся на производительности. Мерой производительности принято считать MIPS (millions of operation per second) — миллион операций в секунду. При тестировании систем для вычислительных задач основным критерием производительности является MFLOPS и GFLOPS миллион и миллиард операций с плавающей точкой в секунду, соответственно. Для массивно-параллельных систем значимой величиной является латентность ЛВС, выражающаяся в среднем времени передачи по сети сообщения нулевой длинны.
Увеличения производительности можно добиться разнообразными способами (не используя изменения на аппаратном уровне): изменение размерности основных величин и/или алгоритма вычислений, определение оптимальной топологии сети. Большой прирост скорости может дать правильный выбор и настройка программного обеспечения (например, опции компилятора). Выбор средств для улучшения можно сделать только после всестороннего тестирования.
Для конкретного метода решения, при помощи соответствующих тестов можно определить масштабируемость данной системы, т.е. зависимость между увеличением числа узлов в кластере и увеличением скорости расчетов. В конечном счете, при росте числа узлов будет наблюдаться увеличение производительности до некоторого предела, после которого, возможно, производительность начнет падать. Это будет обусловлено латентностью ЛВС.
Если объем обрабатываемых данных велик для полного размещения в оперативной памяти системы, то необходимо произвести оценку производительности внешних накопителей и/или файлового сервера.
В процессе настройки, отладки и сдачи кластера имеет смысл сделать объективное сравнение кластера с уже работающими подобными системами. Этот шаг необходим для того, чтобы окончательно убедится, в том, что кластерная система работает и правильно настроена. Чтобы не получилось так, что система из 16 узлов Pentium IV 3000 работает медленнее, чем система из 8 Athlon 1000. Кроме того, заказчику может ни о чем не говорить то, что производительность его кластера составляет 24 GFLOPS.
Что для этого нужно? Benchmarks, benchmarks и benchmarks. Под benchmark'ом (тестом) будем понимать алгоритм или метод, программу или программный комплекс, отвечающий ряду требований [7]:В это группу входят тесты, оценивающие производительность операций, требующих синхронизации, и тесты операционной системы (переключение контекстов, системные вызовы и создание процессов). Часто микротесты объединяются в пакеты тестов.
Из всего множества тестов существуют и такие, которые специально направлены на тестирование массивно-параллельных систем. Наиболее широко они представлены в классе ядер (HPL. NPB ), приложений (NPB ) и тестовых пакетов (SPEC ). Из микротестов большой интерес могут представлять программы, направленные на исследование сетевого окружения (например, Netperf ).
Спецификой ядер и приложений является то, что они «привязаны» к одному из основных алгоритмов численных методов или базовых операции, т.е. к той части программы, выполнение которой занимает наибольшее время. В связи с этим можно заранее выбрать нужный тест, зная, какие задачи будут решаться на кластере. Если расчеты связаны с применением прямых методов решения систем линейных алгебраических уравнений (СЛАУ), то можно использовать Linpack ), в случае применения итерационных методов решения СЛАУ, следует использовать, например, ядра SP, BP из NPB и Iterative Solver Benchmark.
Под базовыми операциями понимается, например, умножение матрицы на матрицу, матрицы на вектора, вектора на вектор, генерирование псевдослучайных чисел, сортировка…
В этой статье позволю себе остановиться на двух тестах: Linpack Benchmark в версии для массивно-параллельных систем — HPL (Portable Implementation of the High-Performance Linpack Benchmark for Distributed-Memory Computers) и NAS Parallel Benchmarks (NPB). Почему именно они? Дело в том, что этим тестам присущи ВСЕ свойства, которые должны быть у тестов:Кроме объективных причин, есть и «необъективные». Одна из них это авторитетность обоих программ (и их авторов). Вероятно, не так сложно разработать тест, отвечающий нужным требованиям, намного сложнее — сделать так, чтобы тест заслужил доверия у многочисленной аудитории.
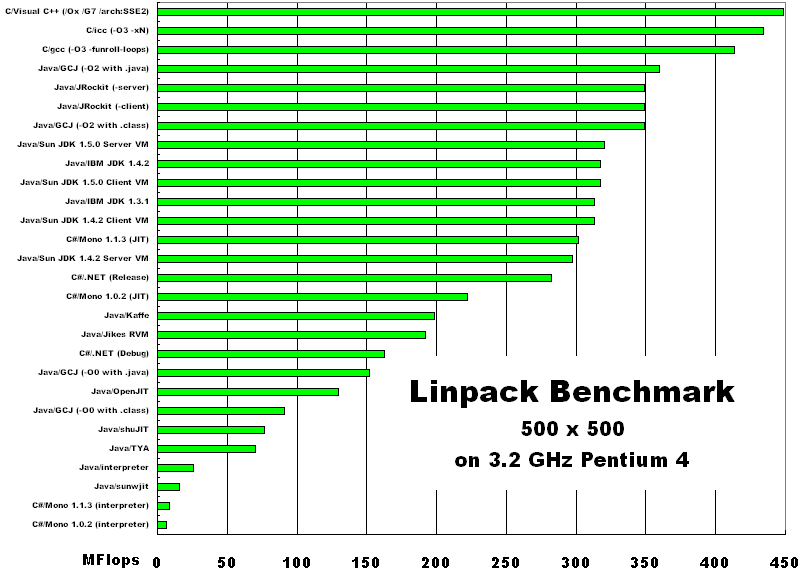
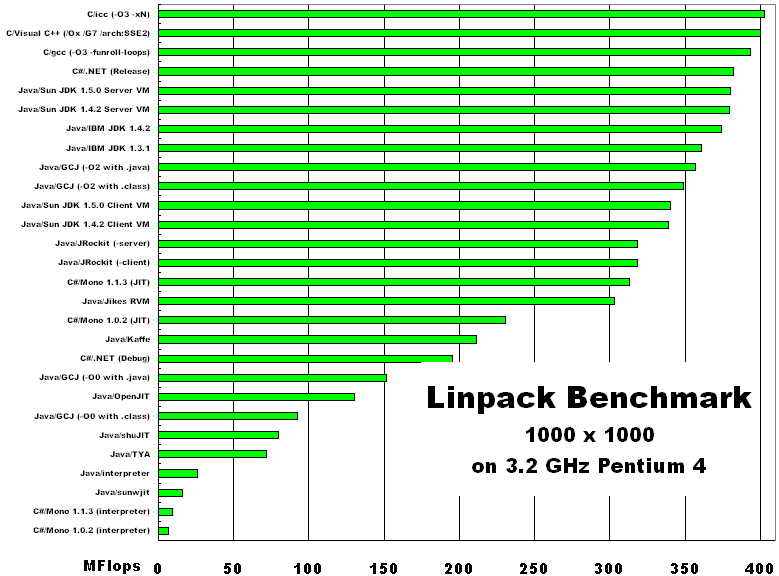
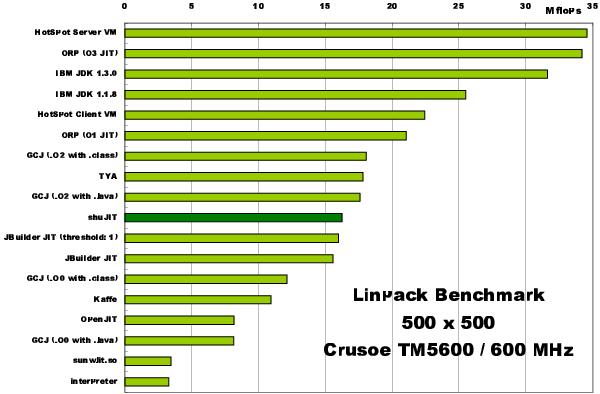
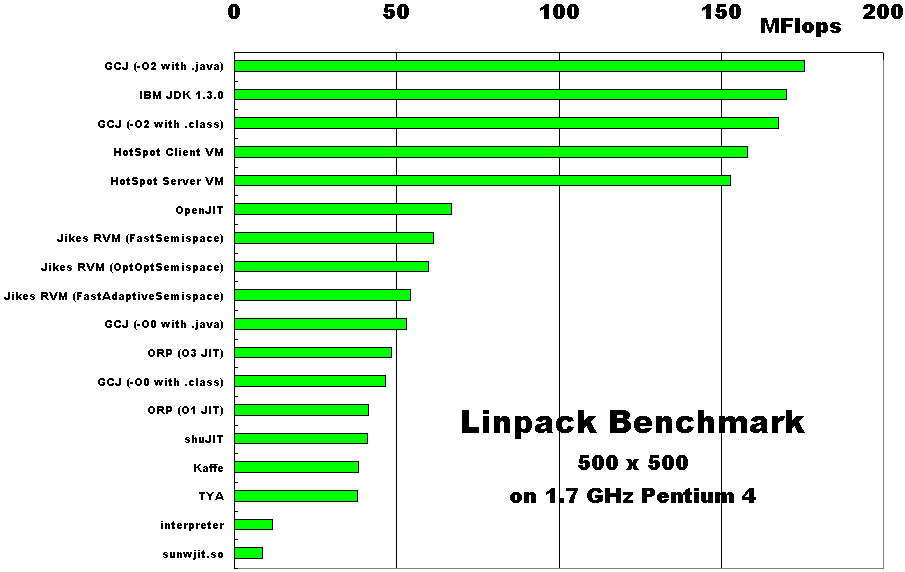
Linpack benchmark Немного историиLinpack benchmark (LB) появился на свет в далеком 1979 году как дополнение к библиотеке Linpack (набор подпрограмм для решения различных СЛАУ) [4]. Целью создания LB было получение возможности оценки времени решения той или иной системы уравнений при помощи пакета Linpack. Основным автором LB можно считать J. Jack Dongarra. С тех пор Linpack был заменен более новым и расширенным пакетом LAPACK. а LB остался средством для сравнения производительности компьютеров при работе с плавающей точкой. С тех пор суть теста не изменилась.
А суть этого теста очень простая — решение СЛАУ Ax=f методом LU-факторизации (LU-разложения) c выбором ведущего элемента столбца. Где A — плотно заполненная матрица размерности N.
Первоначально программа использовалась для тестирования отдельных ЭВМ при помощи матрицы c N=100. С ростом мощностей ЭВМ размерность матрицы была увеличена до N=1000. Эти размерности стали классическими и до сих пор применяются для тестирования на FLOPS отдельных машин. Реализации этих тестов на разных языках можно найти здесь.
Для задач тестирования кластеров используется указанная выше версия теста HPL. В этой версии пользователь имеет возможность задать все значимые параметры алгоритма, подбирая их для наилучшей производительности.
Каждые полгода публикуется отчет о производительности различных компьютерных систем на основе теста LB — Linpack Benchmark report. Кроме того, на сайте www.top500.org представлены 500 самых быстрых компьютеров в мире по версии LB.
Результаты тестов, сделанных при помощи HPL, могут быть предоставлены для рассмотрения на www.top500.org [5].
При параллельном процессе на вычислительном кластере исходная матрица разделяется на логические блоки размерностью NB x NB (обычно NB x NB при расчетах лежит в интервале от 32 — 256). Эти блоки в свою очередь разбиваются сеткой PxQ на более мелкие. Каждый из таких блоков «достанется» отдельному процессору системы. Коэффициенты P и Q берутся в зависимости от структуры кластера, а их произведение не может быть больше доступного числа узлов.
Если в кластере 8 узлов, то допустимыми значениями PxQ будут: 1x8, 2x4, 3x2, 2x2, 1x4… При этом в расчетах будут участвовать PxQ процессоров. Именно процессоров, а не узлов. Конкретные значения P и Q следует выбирать в зависимости от коммуникационной среды.
За одну итерацию главного цикла факторизации подвергаются NB столбцов с последующим обновлением оставшейся части матрицы. Результаты разложения пересылаются всем узлам одним из шести алгоритмов распространения (broadcast algorithm).
После разложения последовательно решается две системы уравнений: Ly=f, Ux=y.
Тест считается выполненным, если rn =O (1), r1 =O (1) и r∞ =O (1), где
rn =||Ax-f||∞ /(||A||1 Nε );
r1 =||Ax-f||∞ /(||A||1 ||x||1ε );
r∞ =||Ax-f||∞ /(||A||∞ ||x||∞ε ).
Эти условия означают, что задача решена верно. Где ε — точность представления чисел с плавающей точкой.
ОсобенностиОсобенностью теста является требование наличия в системе (кроме реализации MPI) любой из следующих библиотек: Basic Linear Algebra Subroutines (BLAS) или Vector Signal Image Processing Library (VSIPL).
NAS Parallel Benchmarks Немного историиЕсли LB появился в конце 70-x начале 80-x, то NPB на целый десяток лет позже — в начале 90-x. NPB появился как дочерний проект при решении агентством NASA задач вычислительной гидродинамики. Цель создания NPB была примерно той же, что и у LB — оценка необходимой мощности аппаратного обеспечения для решения задач гидродинамики. NPB изначально был нацелен на оценку производительности параллельных вычислений на кластерах [1]. На текущий момент стабильной версией является 2.4. Версия 3.0 пока является альфа версией.
По замыслу создателей NPB является «paper and pencil» тестом, т.е. официально NPB только набор правил и рекомендаций, доступных «на бумаге». Правила декларируют практически все вопросы, которые могут возникнуть в процессе разработки:и многое, многое другое.
Помимо всего прочего на сервере NASA доступны готовые реализации теста. В терминах разработчиков — это пример кода (Sample Code), написанный на Fortran-77 и стандарте MPI. До версии 2.0 программа позиционировалась как пример реализации, чтобы упростить создание своей версии конечными пользователями. После версии 2.0 — это законченный продукт. Для скачивания необходимо пройти регистрацию, правда, бесплатную.
Тест состоит из ряда простых синтетических задач: ядер (kernel benchmarks) и псевдо-приложений (application benchmarks), эмулирующих вычисления на реальных задачах (в частности в области вычислительной гидродинамики). В терминологии NPB ядра и приложения могут производить вычисления в определенных классах задач (Problem Classes): «Sample code», «Class A», «Class B» [1], «Class C» [2], «Class D» [3]. В NPB под классом понимается размерность основных массивов данных, используемых в тесте. Другими словами, класс А — это маленькие матрицы, B — большие, С — очень большие, D — огромные. Например, для теста на LU-разложение это будет размерность исходной матрицы: 12 3. 64 3. 102 3. 408 3 для каждого из перечисленных выше классов соответственно. Значения на принадлежность к определенному классу остальных ядер см. ниже.
На текущий момент существует 5 ядер: EP, MG, СG, FT, IS.
Ядро EP — «Embarrassing Parallel» основано на порождении пар псевдослучайных, нормально распределенных чисел (Гауссово распределение). Получаются числа ri О (0,1), где i=0…2n, а n, в свою очередь, определяется классом теста. По замыслу разработчиков этот тест позволяет оценить максимальную производительность кластера при операциях с плавающей точкой при сведении к минимуму межузловых взаимодействий. Эти взаимодействия сводятся к окончательному объединению результатов, рассчитанных на каждом узле независимо от всех остальных. Этот тест может быть полезен, если на кластере будут решаться задачи, связанные с применением метода Монте-Карло. В алгоритме также учитывается время на форматирование и вывод данных.
MG — simple 3D MultiGrid benchmark. Приближенное решение трехмерного уравнения Пуассона D u=f на сетке NxNxN с периодическими граничными условиями (функция на всейгранице равна 0 за исключением заданных 20 точек). Где N определяется классом теста. Функция f — кусочно-постоянная функция равная нулю по всей границе за исключением определенных 20 точек. Этот тест полезен для оценки межузловых соединений.
CG — solving an unstructured sparse linear system by the Conjugate Gradient method (решение неупорядоченной, разряженной СЛАУ методом сопряженных градиентов). Матрица СЛАУ является положительно определенной и симметричной. Метод сопряженных градиентов используется для нахождения приближенного значения наименьшего собственного числа матрицы. В тесте используется обратный степенной метод для нахождения наибольшего собственного числа матрицы.
FT — A 3-D Fast-Fourier Transform partial differential equation benchmark — численное решение уравнения в частных производных δu(x,t)/δt=α D u(x,t), x О R 3 с использованием прямого и обратного быстрого преобразования Фурье. Этот тест включает большое количество действий, оказывающих большую нагрузку на сетевое окружение (перемещение массивов данных).
IS — Parallel Sort of small Integers. Параллельная сортировка N целых чисел. Тест не использует арифметические операции с плавающей точкой. На эффективность теста большое влияние оказывает первоначальное распределение чисел в памяти. Сортировка целых чисел является важной частью метода частиц (particle method).
Кроме ядер, пакет NPB предлагает ряд псевдо-приложений, которые эмулируют работу реальных программ по вычислительной гидродинамике. Отказаться от использования реальных приложений в пользу псевдо-приложений решено по нескольким причинам:Алгоритмы приложений используют описанные выше ядра в том или ином виде и, в конечном итоге, сводятся к решению СЛАУ специального вида (впрочем, как и подавляющее большинство вычислительных задач). Основная масса машинного времени в таких задачах тратится именно на решение СЛАУ. Поэтому приложения можно охарактеризовать как итерационные методы решения СЛАУ. Таких приложений три: LU, SP, BT.
Алгоритмы SP (от Scalar Pentadiagonal) и BT (от Block Tridiagonal) подобны: решение трех несвязанных систем уравнений (в направлениях x, y и z) методом multi-partition scheme. Отличие приложений состоит в структуре матриц: для SP — это пятидиагональная матрица, а для BT — блочная трехдиагональная матрица с размером блока 5x5. Этот метод хорошо распараллеливается и обеспечивает оптимальную загрузку сети, но требует, чтобы количество узлов в кластере было квадратом целого числа. Тест SP более чувствителен к латентности сети.
Приложение LU решает систему уравнений с равномерной разряженной блочной структурой (5x5) методом симметричной последовательной верхней сверхрелаксации (symmetric successive over-relaxation — SSOR), к которой приводят трехмерные уравнения Навье-Стокса. Для распределения данных этому приложению требуется количество узлов, кратных степени двойки. Особенностью этого теста является его критичность ко времени передачи очень маленьких объемов данных между узлами (размер передаваемого сообщения в этом тесте составляет 40 байт).
Принадлежность к определенному классу каждого из приложений определяет размерность системы уравнений. Ниже представлена сводная таблица принадлежности ядер и приложений к определенному классу:
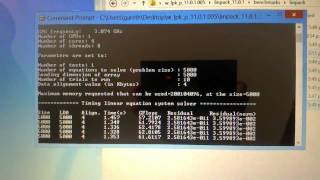












 Вам не нравятся номинальные ограничения скорости процессора, Вы предпочитаете разогнать процессор до предела его возможностей? Если процессор сможет работать быстрее, значит и для памяти можно вслед за ним попробовать увеличить тактовую частоту шины и/или множитель. Разогнать процессор просто, - нужно увеличить его рабочую частоту. Разгон частоты процессора (оверклокинг) может привести к нестабильной работе компьютера, а иногда, что впрочем довольно редко происходит, это может привести и вовсе к выходу компьютера из строя. Ну раз уж Вы решились. Для определения корректности работы процессора в случае разгона полезно будет провести тест стабильности системы при максимальной, пиковой занятости процессора и нагрузке на оперативную память. Иными словами, выяснить, будут ли появляться ошибки процессора и оперативной памяти в режиме повышенной производительности компьютера. Программа LinX это стресс-тест и для ЦП и для RAM.
Вам не нравятся номинальные ограничения скорости процессора, Вы предпочитаете разогнать процессор до предела его возможностей? Если процессор сможет работать быстрее, значит и для памяти можно вслед за ним попробовать увеличить тактовую частоту шины и/или множитель. Разогнать процессор просто, - нужно увеличить его рабочую частоту. Разгон частоты процессора (оверклокинг) может привести к нестабильной работе компьютера, а иногда, что впрочем довольно редко происходит, это может привести и вовсе к выходу компьютера из строя. Ну раз уж Вы решились. Для определения корректности работы процессора в случае разгона полезно будет провести тест стабильности системы при максимальной, пиковой занятости процессора и нагрузке на оперативную память. Иными словами, выяснить, будут ли появляться ошибки процессора и оперативной памяти в режиме повышенной производительности компьютера. Программа LinX это стресс-тест и для ЦП и для RAM.
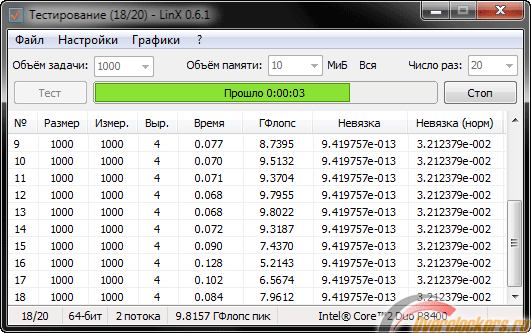
LinX – это абсолютно бесплатная программа, которая предназначена для тестирования стабильности работы процессоров. Она работает с довольно известным тестовым пакетом Intel Linpack. LinX обладает удобным, понятным и простым интерфейсом. На данный момент присутствует два языка – русский и английский. Обнаружив ошибку, программа даст пользователю возможность исправить её, временно остановив тестирование. Присутствует функция автоматического контроля ошибок. Возможна работа с процессорами от компании Intel и AMD. Во время тестирования, приложение автоматически определяет объем доступной оперативной памяти, используя все доступные ресурсы. Это помогает завершить тестирование настолько быстро, насколько это возможно.
LinX работает как с 32-х битными системами, так и с 64-х битными. Для каждой версии операционной системы нужна своя версия Intel Linpack. Настройки последнего тестирования сохраняются, экономя ваше время. Все события (завершение тестирования, обнаружение ошибок и так далее) сопровождаются звуковыми сигналами. Присутствует расчет времени до окончания тестирования. Значения температуры, оборота вентиляторов, напряжения возможно импортировать с программ мониторинга системы вроде Speedfan и Everest. LinX сам построит графики. Можно делать скриншоты графиков, сохраняя их в формате PNG. В новых версиях программы можно ставить тестирование только на определенный промежуток времени, по завершении которого оно будет остановлено.
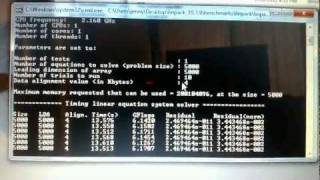
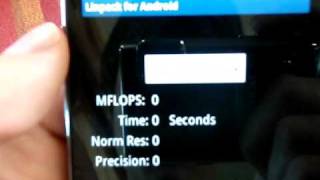
Linpack Benchmark - утилита представляет собой бенчмарк, который измеряет производительность системы при работе с плавающей точкой. Чем большее количество прогонов (Number of runs), тем точнее результат производительности системы. С помощью этого теста удобно сравнивать разницу в производительности, к примеру, новых и предыдущих моделей iPhone.
Отзывы о Linpack Benchmark 1.4 для iPhone, iPad, iPod Opera Mini
Opera Mini
AccuWeather.com
World of Tanks Blitz
ICQ Mobile
Temple Run 2
TeamViewer
Color Splash for iPad
123D Sculpt
Здравствуй уважаемый читатель! В этой статье проведём Стресс тест компьютера на стабильность, программой OCCT (OverClock Checking Tool) на момент написания этой статьи самой последней версии 4.4.1.
При помощи программы OCCT мы сможем провести тест следующих компонентов нашего ПК:
Программа OCCT при прохождении теста даёт максимальную нагрузку на тестируемые компоненты нашего ПК. И если тестирование закончилось без ошибок, то ваш ПК и система охлаждения полностью исправны, и выходить из строя пока не собираются!
Установка стандартная после запуска скаченного установочного файла в первом окошке жмём «Далее» во втором жмём «Принимаю» в третьем «Далее» и в четвёртом окне кнопочку «Установить»
После установки на рабочем столе у вас появится вот такой значок программы OCCT
Запускаем программу с ярлыка. И пред нами появляется примерно вот такое окно.
Почему примерно, потому, что окно программы меняется в зависимости от настроек, у меня программа уже настроена, и у вас в итоге после всех настроек получится тоже самое окно программы, а дальше уже «наученные» будите менять его по своим интересам.
И так, приступим к настройке программы OCCT .
В главном окне программы кликаем на вот по этой кнопочке
Попадаем в окно настроек
В этом окне самое главное проставить температуры при достижении которых тест будет остановлен, это не обходимо для предотвращения выхода из строя какого либо узла от перегрева.
СОВЕТ – Если у вас достаточно новый ПК, то температуру можно выставлять 90°С. У комплектующих последних выпусков достаточно высокие рабочие температуры.
Но если вашему ПК 5 и более лет, то выставляйте температуру 80°С. Более позднего выпуска детали очень чувствительны к перегреву.
Самый оптимальный вариант, посмотреть предельно допустимые температуры вашего железа на сайте производителе.
Комплектующие в разгоне тест не проходят! Программа OCCT даёт такую нагрузку, что темперартура переваливает за 90°С и останавливает тест.
От 90°С до 100°С и выше, это критическая величина, при которой детали на на ваших комплектующих начнут отпаиваться из своих сёдел, если не успеют сгореть раньше.
Но панически боятся сжеть систему не стоит! «Повторюсь» Главное перед прохождением теста, проверить на работоспособность все вентиляторы (Кулера) в системном блоке и почистить от пыли систему охлаждения.
А проводить тест компьютера на стабильность нужно обязательно! Для того, что бы выход из строя ПК (допустим в момент написании какого ни будь архи важного для вас материала) не стал неожиданностью.
После решения вопроса по температурам. В последней колонке настроек которая называется «В реальном времени» ставим галочки для графиков которые мы хотим видеть при прохождении теста.
Так с настройками разобрались, можете закрывать их.
Теперь приходим обратно к главному окну программы.
В главном окне программы находятся четыре вкладки. CPU:OCCT, CPU:LINPACK, GPU:3D и POWER SUPPLY.
Тест Процессора, Оперативной памяти, и Материнской платы — CPU:OCCTТут для начала выставляем значения: Для удобства я их пронумеровал.
1. Тип тестирования: Бесконечный – Тест будет идти без времени, пока сами его не остановите. Авто — Тест будет проходить по времени выставленном в пункте 2. Длительность.
Рекомендованное автором программы время для прохождения теста 30 минут, но самое оптимальное время это 1 час. Если с железом есть проблемы, то за 1 час они точно покажут себя!
3. Периоды бездействия – Время до начало теста, и после окончания. Отчёт которого вы увидите в окне программы после запуска теста.
4. Версия теста – Разрядность вашей системы. У меня программа сама определила разрядность при первом запуске.
5. Режим тестирования – Тут выбираем в выпадающем меню один из трёх наборов: Большой, Средний, и Малый.
Большой набор – Тестируются на ошибки Процессор, Оперативная память, и Материнская плата (чипсет).
Средний набор – Тестируются на ошибки Процессор и Оперативная память.
Малый набор – Тестируется на ошибки только Процессор.
6. Number of threads (Количество потоков) – Выставляем количество потоков которое поддерживает ваш процессор. У меня программа сама определила количество потоков процессора.
 Здравствуйте Друзья! В этой статье проведем диагностику комплектующих с помощью мощнейшего теста компьютера на стабильность — OCCT. Тест OCCT расшифровывается как OverClock Checking Tool. Это специальная утилита способная по максимуму нагрузить компоненты вашего компьютера подвергая их все возможным тестам для выявления ошибок. Другими словами с помощью OCCT можно провести стресс тест компьютера на стабильность .
Здравствуйте Друзья! В этой статье проведем диагностику комплектующих с помощью мощнейшего теста компьютера на стабильность — OCCT. Тест OCCT расшифровывается как OverClock Checking Tool. Это специальная утилита способная по максимуму нагрузить компоненты вашего компьютера подвергая их все возможным тестам для выявления ошибок. Другими словами с помощью OCCT можно провести стресс тест компьютера на стабильность .
OCCT оповещает пользователя о найденных ошибках. Если таковые нашлись, значит действительно что то не в порядке. В повседневной работе, возможно, ошибки не будут заметны, так как вы не подвергаете свой компьютер таким нагрузкам. Но она с огромной вероятностью появится в будущем рано или поздно. Не исключено, что это будет в виде синего экрана смерти. Что бы избежать таких неожиданностей можно и нужно протестировать свой новый или обновленный компьютер.
Как утверждает разработчик OCCT большинству пользователей будет достаточно 30 минутного теста. Но для большей надежности желательно запускать тесты длительностью в 1 час.
1. Скачивание и настройка теста компьютера OCCTСкачать OCCT можно и нужно с официального сайта http://www.ocbase.com/
Переходите на вкладку Download и в самом низу будут ссылки для скачивания
Мне нравится Zip Version так как она не требует установки.
Запускаем OCCT.exe
Внешний вид программы вы можете наблюдать на рисунке ниже
Окошко справа мониторинг может незначительно отличаться. Это окошко настраивается. Для этого нажимаем в левом окошке на оранжевую кнопку 
В открывшихся опциях в последней колонке можно настроить, что будет отображаться в окошке Мониторинг
Мои настройки вы можете видеть на рисунке выше
После этих настроек окошко Мониторинг обретает следующий вид
Вверху загрузка процессора и частота, в центре температуры внизу частота вращения вентилятора процессорного кулера.
2. Тест процессора, памяти и материнской платы — CPU:OCCTЧто бы протестировать процессор, память и материнскую плату а точнее чипсет материнской платы воспользуемся вкладкой CPU:OCCT
Тип тестирования устанавливаем Авто .
Длительности и периоды не трогаем
Версия теста у меня установилась автоматически правильно — 64 бит. Соответствует разрядности вашей операционной системе. (Для того что бы посмотреть разрядность вашей системы заходите в Пуск на пункте Компьютер нажимаете правой кнопкой мышки и выбираете Свойства. В открывшемся окошке в разделе Тип системы увидите разрядность вашей Windows)
Режим тестирования. Из выпадающего списка можно выбрать Малый, Средний или Большой набор данных. По непроверенным, но достоверным источникам при выборе Малого объема данных тестируется только процессор на ошибки. При выборе Среднего объема данных тестируется процессор и оперативная память. При выборе Большого объема данных тестируется процессор, память и чипсет материнской платы.
Выбираем Большой набор данных.
Number of threads — количество потоков. Устанавливаем галочку — Авто дабы задействовать все возможные. Тестируемый процессор Intel core i3 2125 двухъядерный, но благодаря технологии Hyper-threading каждое физическое ядро может тянуть сразу два потока. То есть получается 4 логических ядра.
Перед запуском теста желательно закрыть все работающие программы и выйти из программ которые висят в области уведомлений.
Когда все готово нажимаем  и оставляем компьютер на 1 час.
и оставляем компьютер на 1 час.
По окончанию теста откроется проводник по адресу C:\Users\Anton\Documents\OCCT\
В папочке с текущей датой будут графики различных параметров от загрузки процессора. Там все наглядно показано.
Если в ходе теста обнаружатся ошибки вы увидите предупреждение. Что делать в этом случае читайте в Заключении.
3. Тест процессора — CPU:LINPACKДанный тест сильно грузит только процессор. Он прогревает его лучше чем CPU:OCCT
Не рекомендуется запускать на ноутбуках. нетбуках и другой портативной технике так как система охлаждения там слабенькая.
Тип тестирования выбираем Авто. Длительность и периоды бездействия оставляем как есть
Память так же оставляем как есть .
Если у вас 64 разрядная система ставим соответствующую галочку.
Если ваш процессор поддерживает расширение системы команд AVX — ставим соответствующую галочку.
Вот выдержка из Википедии
У меня процессор Sandy Bridge поддерживающий AVX поэтому галочку устанавливаю.
Так же устанавливаем если не стоит галочку Использовать все логические ядра.
Запускаем тест и один час не трогаем компьютер.
По окончании теста просматриваем графики с температурами. Если в ходе теста ошибки не были обнаружены и температуры в норме, значит все в порядке. Иначе смотрим Заключение.
4. Тест графического адаптера — GPU:3DДля проверки видеокарты переходим на вкладку GPU:3D
Тип тестирования: Авто . Длительности и периоды бездействия не трогаем.
Версия DirectX — 11. Для стареньких видеокарт лучше устанавливать DirectX9.
В разделе Видеокарта выбираем необходимый графический адаптер для теста. Например у вас ноутбук и можно выбрать встроенную или дискретную графику. Если у вас несколько видеокарт в связке, то, скорее всего, здесь можно выбрать конкретную.
Разрешение. Из выпадающего списка мне кажется целесообразно выбрать разрешение своего монитора .
Затем устанавливаем галочки для включения полноэкранного режима и включения проверки на ошибки.
Сложность шейдеров. При наведении на это поле мышкой внизу в разделе Помощь показывается подсказка
То есть для видеокарт AMD выбираем 7, для NVIDIA — 3. Так как у меня встроенная графика от Intel оставляю по умолчанию.
Использование памяти. Ограничение объема памяти для тестирования. Мне кажется галочку желательно не устанавливать. Пусть использует сколько нужно.
Ограничитель кадров так же оставляю по умолчанию .
Запускаю тест и час не трогаю компьютер. Затем смотрю были ли ошибки и просматриваю графики с температурами. Если температура в норме и ошибок не было не волнуюсь. В противном случае смотрите Заключение.
5. Тест блока питания — POWER SUPPLYПереходим на последнюю вкладку POWER SUPPLY. В этом тесте нагружается все, что можно и за счет этого происходит диагностика Блок питания. Держит ли он нагрузки или нет.
Настройки устанавливаем как обычно
Если у вас Windows 64 битный — устанавливаем галочку 64 бит Linpack. Остальные галочки если не установлены так же ставим.
Запускаем тест
Час мне выдержать не удалось, остановил тест на много раньше так как со встроенной графикой нормально протестировать 500 Вт блок питания не получится.
После завершения теста смотрим не было ли ошибок и просматриваем графики. Если все нормально, то можно продолжать работать дальше. В противном случае смотрите Заключение.
ЗаключениеЧто делать если тест компьютера на стабильность закончился с ошибками или был обнаружен перегрев? Во первых самое простое можно очистить компьютер от пыли. Затем, если это не дало должного результата, можно заменить термопасту на процессоре . Если видеокарта на гарантии лучше отнести ее в сервисный центр. Если гарантия прошла можно заменить термопасту на графическом чипе.
Что бы исключить блок питания из подозрения можно на время проверки поставить другой, более мощный. Если тест не проходит необходимо убрать разгон если таковой имел место быть. Если процессор или видеокарта не были разогнаны и при тестировании дают сбои нужно нести по гарантии. Если последняя закончилась, то можно попробовать снизить тактовые частоты (сделать это возможно с помощью утилит к материнской плате и с помощью MSI Afterburner ). Если не помогает, то стоит задуматься над заменой компьютера или апгрейде.
Мое видение по поводу нормальной температуры комплектующих можно посмотреть здесь .
Благодарю, что поделились статьей в социальных сетях. Всего Вам Доброго!
LinX 0.6.4
Изменения:
- добавлена возможность запустить тестирование на заданный временной интервал и новое выпадающее меню для переключения между двумя режимами (разы/минуты)
- небольшие изменения/улучшения пользовательского интерфейса
- окна графиков теперь корректно сохраняют свои позиции при выходе из программы
- исправлен не очень частый баг с ошибками LinX при сильной загрузке процессора
- добавлены новые параметры командной строки, исправлены найденные ошибки в старых (LinX.exe -help для вывода доступных параметров)
- добавлены секунды в имена файлов для избежания переименования
Скачать / Download LinX 0.6.4
LinX 0.6.4 AVX (Linpack 10.3.10.017) с поддержкой AVX
Изменения:
Версия Intel Linpack заменена на 10.3.10.017