



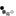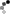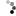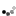 Рейтинг: 4.8/5.0 (1858 проголосовавших)
Рейтинг: 4.8/5.0 (1858 проголосовавших)Категория: Windows: Антивирусы
This guest post is by Dave Hoover . who authored the book Apprenticeship Patterns: Guidance for the Aspiring Software Craftsman for O’Reilly, instigated the Software Craftsmanship North America conference. and is the Chief Craftsman at Obtiva. Dave began teaching himself to program in 2000, back when he was a family therapist. Dave lives near Chicago with his wife and three children. In his spare time, Dave competes in endurance sports.
 Web developers can sometimes forget the importance of doing as little work as possible during the HTTP request-response life-cycle. When we’re developing new features, the simplest thing to do is just handle all the work that has been requested before responding, making the user wait, patiently watching their browser spin. This is nearly always a bad idea, and for reasons beyond user experience, most notably, it ties up a web process, making your site more likely to experience outages as traffic spikes. While it often makes sense to develop features with slow responses for your initial implementation, it’s usually unwise to deploy that version of the feature to your production environment. Thankfully, Ruby developers can choose from a number of “background job” libraries. I’m going to introduce you to Resque. developed at Github. built on top of Redis. an advanced key-value store which Resque uses for queuing.
Web developers can sometimes forget the importance of doing as little work as possible during the HTTP request-response life-cycle. When we’re developing new features, the simplest thing to do is just handle all the work that has been requested before responding, making the user wait, patiently watching their browser spin. This is nearly always a bad idea, and for reasons beyond user experience, most notably, it ties up a web process, making your site more likely to experience outages as traffic spikes. While it often makes sense to develop features with slow responses for your initial implementation, it’s usually unwise to deploy that version of the feature to your production environment. Thankfully, Ruby developers can choose from a number of “background job” libraries. I’m going to introduce you to Resque. developed at Github. built on top of Redis. an advanced key-value store which Resque uses for queuing.
One nice thing about Resque is that it’s not dependant on Rails or any web framework. This is great, because today, I’m not interested in writing a web application. I want to write a fast-running Ruby program that figures out what work needs to be done, tells someone else to do it, and then exits. (Similar to a web request, but simpler.) I’ll start with this:
If I named this program idea_analyzer.rb and it was in my current working directory, I could run it like this:
As you can see, this program takes an “idea” from the command line and claims to ask for a “job” to analyze each word in the idea. Obviously, the next step is to actually ask for that job, instead of just talking about it. First, I’ll write the code that tells Resque to enqueue a job, and then we’ll get Resque in place. That might seem backward to some of you, since I’m writing code I know will fail, but “fast-failure” is a technique I use all the time, whether I’m practicing test-driven development. or learning a new technology with a toy problem like this:
Nice and simple. We’re calling a method on the Resque class. We’re passing in the word, but we’re also passing in the class WordAnalayzer. This is the only code that interacts directly with Resque. The enqueue method takes the name of the class responsible for doing the background work and the data required to accomplish the work, in this case the word variable. It will attempt to place a job in the appropriate queue. If we run the current version of this program, it fails like this:
The uninitialized constant Resque error is telling me that Ruby doesn’t know about Resque yet. I can fix that by installing the Resque gem.
You’ll likely see other gems being installed as well, these are the gems that Resque depends on. Now I’ll just tell our program about Resque:
When we run this, we’ll get a different error. Excellent! We’re making progress.
If you see an error like no such file to load -- resque. then you need to add require "rubygems" at the top of your program. You should eventually see the error about a missing WordAnalyzer. I’ll take care of that next by creating a word_analyzer.rb file, defining the class…
…and then require it.
And this fails with a different error, we’re almost there!
Now our problem is that we haven’t specified a queue for the WordAnalyzer class. As its name suggests, Resque is all about queues. Each Resque class, such as WordAnalyzer. can specify its default queue, like this:
Re-running this results in:
Resque is trying to enqueue a WordAnalyzer job for “I” on the word_analysis queue, and is using the default host (localhost) and port (6379). I’ll start Redis and our program should be much happier. I recommend installing Redis via https://github.com/antirez/redis/archives/master with antirez-redis-v2.0.3-stable-0-gb766149.zip. Then starting it in a new console with redis-server. With that running, you can rerun your program and it should look like the output of the first version:
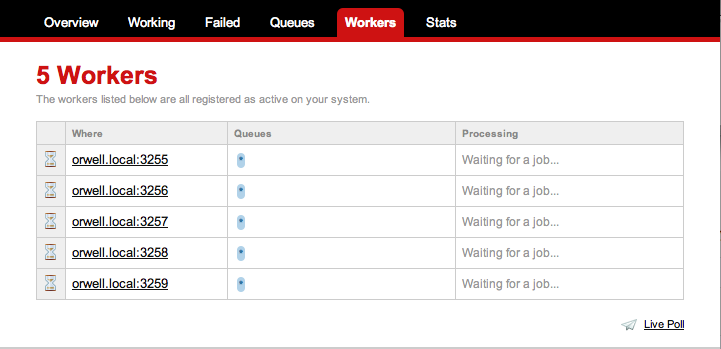
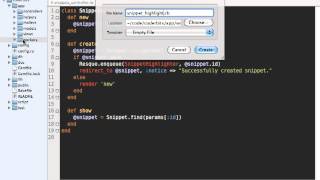
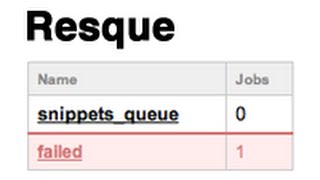
But this time, after its quick run, it has left some work behind, sitting in Redis. You can see it if you type resque-web in your console. This will launch a browser and bring up a little Sinatra app that ships with Resque, allowing you to watch the activity between Resque’s queues and workers. Now that we can see 4 jobs waiting patiently in the word_analysis queue, let’s get a worker started. The customary way to start Resque workers is via Rake, so I’ll create a Rakefile beside my other 2 files and just put this in the Rakefile :
Then, from the command line, I can start the worker with:
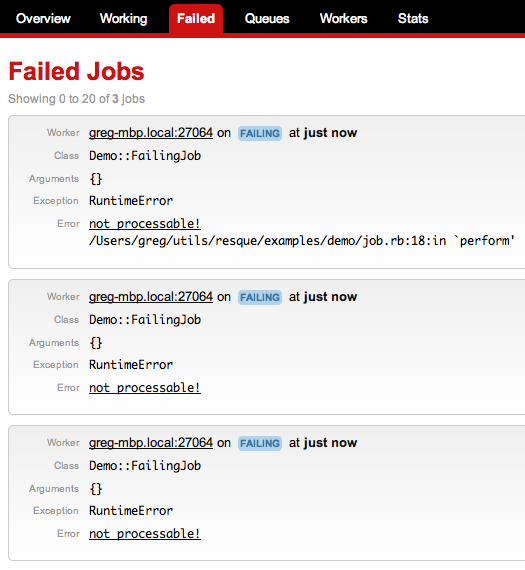
This will start a worker listening on all of Resque’s queues, and will never exit. If you want to stop it, just hit CTRL-C. Once it has run for a few seconds, refresh the browser you had pointing at resque-web, click-through to the failure queue, and you’ll see all the jobs failed with undefined method 'perform' for WordAnalyzer:Class. That’s a nice way of telling us it’s time to write the perform method for our Resque class:
If your worker is still running, stop it with a CTRL-C. Then restart it via Rake so it loads up our new perform method. As you’ve probably guessed, Resque simply calls a method named perform on the class you enqueue. Be aware that any arguments you pass into Resque.enqueue are going to be serialized as JSON. which means Ruby Symbols will turn into Strings, and complex objects like instances of ActiveRecord will not work. When I need to work with ActiveRecords in Resque, I just pass their ids across and re-query them from the database.
Now that the worker is restarted and WordAnalyzer knows what to perform, our background processing system is ready. Start a new console and execute ruby idea_analyzer.rb I will learn ruby. Your Resque worker should perform some “successful” analysis over the course of about 12 seconds:
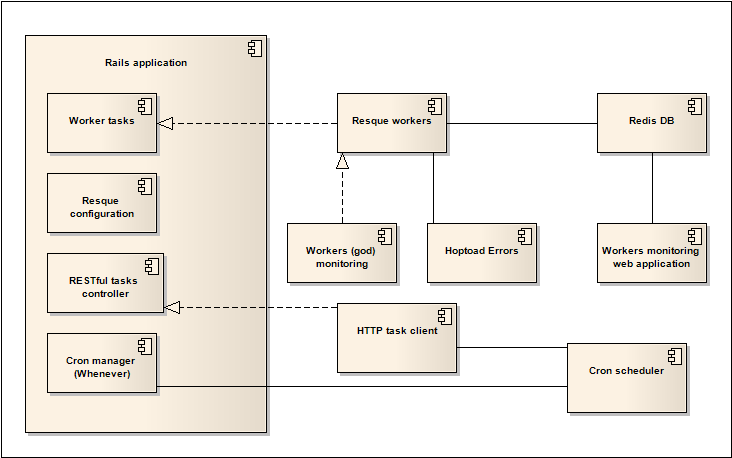
That’s all there is to it. You can keep running your idea_analyzer.rb and the worker will keep analyzing words. Here is a visual workflow of this little system that may help clarify the different roles:
We have a fast running program that queues work for later. We have a simple class that performs a time-consuming job, managed by a long-running Resque worker. We also have a web interface to monitor our queues and workers. These are the building blocks used by large-scale web sites like Github. Mad Mimi. and Groupon. who leverage Resque for their mission critical background processing.
I hope you found this article valuable. Feel free to ask questions and give feedback in the comments section of this post. Thanks!
Do also read these awesome Guest Posts:

















The GitHub guys recently released their background processing app which uses Redis: http://github.com/defunkt/resque http://github.com/blog/542-introducing-resque I have it working locally, but I'm struggling to get it working in production. Has anyone got a: Capistrano recipe to deploy workers (control number of workers, restarting.
Resque or Gearman - choosing the right tool for background jobsWe are developing a web application wherein with about 50% of write requests, we end up pushing data to multiple data stores and inserting and updating significant number of records in those data stores. To improve the response time, we want to process such requests asynchronously in the background. Our web application is being written.
How to use resque-scheduler and resque-status together?I have resque-scheduler working fine in a rails app. Now I need to be able to track status and remove jobs from the queue. I had a brief look at resque-status and, from what I saw, if I could get it to play nicely with resque-scheduler then it would be perfect. However, it seems rescue-status uses create which wraps enqueue and resque-s.
Rails Resque workers fail with PGError: server closed the connection unexpectedly Guide to migrate from delayed_job to resque? Resque Runtime Error at /workers: wrong number of arguments for 'exists' command Connect resque to other key-value DB than redis? Resque: Slow worker startup and Forking Have Rails 2.3.x ignore the i18n gem Why I'm getting stack level too deep while triggering a job using resque-status? How to change the default sleep time (5s) of resque? How to set expire time when add a task to resque? Odd reload! behavior in console when creating Resque jobs What's the best way to write Resque-related specs in RSpec? How to force heroku to use JSON/ext over JSON/pure.I've hit a stumbling block and I'm not sure how to proceed. I'm trying to get resque working with redis to go on heroku, I have it all working locally, but when I push to my staging environment and try to queue a job I get the following exception: TypeError: wrong argument type JSON::Pure::Generator::State (expected Data) On my local m.
Net::SSH connection fails from inside resque jobI have an app that sets creates EC2 instances - I have a resque task that will configure the server (via ssh) once it's up and running: Net::SSH.start(server.dns_name, 'root'. keys => ['
/.ssh/testkey.pem']. paranoid => false. verbose => :debug) do |ssh| result = ssh.exec!("ls -l") puts result end I get an.
Resque Scheduler on Heroku. Do it remotely ?Hi! I'm adding Resque-Scheduler in my app on Heroku So. I need ONE alone and distinct worker acting as the scheduler and many doing the jobs. This is how I've done it. I've a distinct Heroku App which does nothing but has 1 resque-scheduler worker, running 24/7, adding Resque tasks to the Redis DB of the "distant" main App. (I do t.
Resque plugin's resque-web is not running. Resque Scheduler plugin for the scheduled job not working.Showing blog posts tagged as "Resque"
Using Redis with Ruby on RailsThursday, 24 March 2011
Buy The Redis Book!Written by Redis creator, Salvatore Sanfilippo, and key contributor, Pieter Noordhuis, the Redis Book will show you how to work with different data structures, how to handle memory, replication, and the cache itself, and how to implement messaging, amongst other things! Buy the book
Redis is an extremely fast, atomic key-value store. It allows the storage of strings, sets, sorted sets, lists and hashes. Redis keeps all the data in RAM, much like Memcached but unlike Memcached, Redis periodically writes to disk, giving it persistence.
Redis is an open source, advanced key-value store. It is often referred to as a data structure server since keys can contain strings, hashes, lists, sets and sorted sets.
You can run atomic operations on these types, like appending to a string; incrementing the value in a hash; pushing to a list; computing set intersection, union and difference; or getting the member with highest ranking in a sorted set.
In order to achieve its outstanding performance, Redis works with an in-memory dataset. Depending on your use case, you can persist it either by dumping the dataset to disk every once in a while, or by appending each command to a log.
The above quote was taken from the official Introduction to Redis page.
Table of Contents Redis Data TypesBelow is a general overview of the data types available to you in Redis:
Oct 30 th. 2011
Resque is a fast, lightweight, and powerful message queuing system used to run Ruby jobs asynchronously (or in the background) from your on-line software for scalability and response. I needed to integrate software written in different languages and environments for processing, and this is my understanding of the implementation.
How Queuing with Redis worksResque’s real power comes with the Redis “NoSQL” Key-Value store. While most other Key-Value stores use strings as keys and values, Redis can use hashes, lists, set, and sorted sets as values, and operate on them atomically. Resque leans on the Redis list datatype, with each queue name as a key, and a list as the value.
Jobs are en-queued (the Redis RPUSH command to push onto the right side of the list) on the list, and workers de-queue a job (LPOP to pop off the left side of the list) to process it. As these operations are atomic, queuers and workers do not have to worry about locking and synchronizing access. Data structures are not nested in Redis, and each element of the list (or set, hash, etc.) must be a string.
Redis is a very fast, in-memory dataset, and can persist to disk (configurable by time or number of operations), or save operations to a log file for recovery after a re-start, and supports master-slave replication.
Redis does not use SQL to inspect its data, instead having its own command set to read and process the keys. It provides a command-line interface, redis-cli. to interactively view and manipulate the dataset. Here is a simple way to operate on a list in the CLI:
How Queuing with Resque worksResque stores a job queue in a redis list named “resque:queue:name”, and each element is the list is a hash serialized as a JSON string. Redis also has its own management structures, including a “failed” job list.
Resque namespaces its data within redis with the “resque:” prefix, so it can be shared with other users.
Designed to work with Ruby on Rails, Resque jobs are submitted and processed like the following boilerplate:
This does not serialize an object to the queue, instead it saved the (ActiveRecord) model name and record id which is re-instantiated from the database later. The additional arguments are saved in an array to call later. To keep the operation light, do not pass a lot of data to the job. Instead pass references to other records, files, etc.
Each job in Resque is a hash serialized as a JSON string (remember data structures can not be nested in Redis) of the format:
When the job is popped from the queue, Resque instantiates the ActiveRecord object and calls its process method, passing the additional parameters. Functionally, the worker code behaves something like this (simplified):
If processing raises an exception, the job and relevant information is placed on the failed list of the JSON format (as a string):
A failed job can be retried (only once though) through the web interface started with the resque-web command.
Using Resque without Rails Calling external systems with ResqueThere are ports of Resque to other languages such as python, C, Java. NET, node, PHP and Clojure. If your external system is written in one of these languages, then you can start workers listening to their queues. Since you are not talking to a ruby class with arguments, you can set up a placeholder class with the proper queue name. This will allow Resque plugins to fire on enqueue. (I assume the other libraries work the same way as the original, though some of the languages are not object-oriented—I have not verified them.)
That class does not have to implement process() since that will be called in the real class.
If you need to call an external system to perform the task, either that system can be written to accept Resque-style queuing requests (hash of “class” and “args”), or you can push the expeted format directly to the queue
The format does not have to be json, but has to be a string of a format the external system expects. You can not use the Resque workers
Calling the Ruby Resque from an external systemI’ve put off some scaling related issues about as long as possible, and am now proceeding to introduce a deferred-job stack. I’ll explain what I’ve learned so far, and with the caveat: this isn’t in production yet. I’m still learning.
What it’s all aboutTools like Resque let you perform work asynchronously. That way, you can turn requests around quickly, so the user gets something back immediately, even if it’s just “Thanks, we got your request”, which is nicer than the user waiting around 5 minutes, and ensures your server doesn’t lock up in the process. Typical example being sending an email – you don’t want the user’s browser to wait while your server connects elsewhere and fires off the email. Other examples would be fetching a user’s profile or avatar after they provide their social profile info; or generating a report they asked for.
So you set up an async job and respond telling the user their message is on the way. If you need to show the user the result of the delayed job, make the clien polls the server and render the result when it’s ready. More power XHR!
The simple way to do thisThe simple way, which worked just fine for me for a long time and I’d recommend for anyone starting, is a simple daemon process. Basically:
Resque is a queueing system that is backed by Redis. Common use cases include sending emails and processing data. For more information about Resque itself, visit http://github.com/defunkt/resque. This tutorial will cover setting up Resque with Rails and Redis To Go.
Set Up RailsThis is going to be a Rails 3 app, so get the latest gem.
Create the application:
Modify the Gemfile to include Resque.
Install all of the gems and dependencies using Bundler .
Set Up Redis To GoGo to Redis To Go and sign up for the free plan. Once you have an instance, grab the URL given to you and modify the config/initializers/resque.rb as follows:
Create a JobJobs are Ruby classes or modules that respond to the perform method. A good place to put jobs that perform background work would be in app/jobs. Create the job named Consume in app/jobs/eat.rb
Inside config/initializers/resque.rb place the following code so that app/jobs/eat.rb is loaded.
Enqueue the JobThe main use case for using a queuing system is to take prevent a task that could take more than a second from blocking a request. This will often happen in either the model or controller. Create a controller named eat .
Create the action in the controller. This action will put a job on the queue and return the request, leaving any work to be done outside of the request.
Start a WorkerTo start a worker that will pull work off of all queues run the command:
Start the ServerIn a separate terminal start the rails server.
Test the ApplicationPull up a browser and go to http://localhost:3000/eat/cookie. You should get the following response.
In the terminal where you started the worker it should have outputted:
IntrospectionOne of the most useful aspects of Resque is the ability to perform introspection. Resque has a great interface that can be give you and understanding of what is going on. The best part is that you can load it in a subpath with Rack's URLMap .
Open config.ru and replace what is in the file with the following code. This will boot your app as the root and give you /resque as the web front end to Resque.
From /resque you can see what is in your queues, the workers and what they are currently doing, and the ability to view any failed jobs.
Deploy to HerokuThis part can be done two different ways, using the Heroku Redis To Go add-on or signing up for directly.
The only adjustment that we need to make is to map the rake task jobs:work to resque:work and set the queues to watch. After making these changes the Heroku workers will work wonderfully. Open lib/tasks/resque.rake and replace what is in there with the following:
Now create the Heroku app and deploy.
Now if you got to the /eat/cookie a job will be placed on the Resque queue. You can view the queue from /resque
ConclusionThis should get you up and running with Resque and on your way to a scalable solution. If you run into any issues please don't hesitate to reach out to us at support@redistogo.com!
In this episode we’ll take a break from our series on the new features of Rails 3.1 and take a look at Resque which is a great way to handle background jobs in Rails applications. We’ve covered several ways of handling background processing in previous episodes; each one serves a slightly different need and Resque is no exception. At the end of this episode we’ll give you some tips on choosing the right one to fit your needs but for now, let’s dive into Resque and add it to a Rails application.
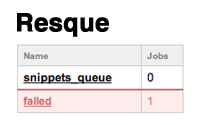
The application we’ll be using is a simple code-sharing snippet site a little like Pastie. With this site we can enter a code sample and give it a name and language.
When we submit a snippet it is shown with the appropriate syntax highlighting for the selected language applied.
The syntax highlighting is handled by an external web service and it’s this part of the code that we want to be handled by a background job. It is currently executed inline as part of the SnippetController ’s create action.
The syntax highlighting happens when the snippet is saved. It uses the service available at http://pygments.appspot.com/. which was set up by Trevor Turk, to provide highlighting without using a local dependency. The code makes a POST request to the service, sending the plain code and the language, and populates the snippet’s highlighted_code attribute with the response from that request.
Communicating with external services through a Rails request is generally a bad idea as they might be slow to reply and so tie up your entire Rails process and any other requests that trying to connect to it. It’s much better to move external requests out into an external process. We’ll set up Resque so that we can move the request into a Resque worker.
Getting Resque RunningResque depends on Redis which is a persistent key-value store. Redis is fairly awesome in itself and well worth an episode on its own, but here we’re just going to use it with Resque.
As we’re running OS X the easiest way to get Redis installed is through Homebrew which we can do by running this command.
Простота использования:
Стабильность:
Интерфейс программы: русский
Платформа: XP / 7 / Vista
Производитель: Kaspersky Lab
Сайт: www.kaspersky.ru
Kaspersky Rescue Disk является загрузочной утилитой для сканирования, лечения дисков и восстановления данных после вирусных атак. Данная программа имеет довольно широкие возможности и позволяет восстанавливать систему даже, казалось бы, в самых критических случаях, когда систему даже не представляется возможным запустить.
Основные возможности программы Kaspersky Rescue DiskНачнем с того, что данная утилита позволяет произвести сканирование, удаление вирусов и восстановление данных даже в том случае, когда инфицирован загрузочный сектор самой операционной системы, и до загрузки «операционки» даже не доходит.
Для того чтобы использовать данную программу, необходимо записать ее на любой съемный носитель, включая различного рода диски, USB-совместимые устройства или съемные карты памяти. При загрузке операционной системы необходимо зайти в настройки приоритета загрузки в BIOS и выбрать необходимое устройство. При запуске после перезагрузки программа автоматически произведет сканирование всех устройств на предмет содержания вирусов, троянов, червей, вредоносных кодов или шпионского программного обеспечения. И это является огромным плюсом программы, поскольку, она может работать с любого носителя (в отличие, скажем, от AVP Tool, которая работает под управлением операционной системы).
В числе нововведения в десятом релизе стоит отметить возможность лечения объектов автозапуска, наличие эвристического анализатора, поддержка различных файловых систем (NTFS, FAT32, FAT16, Ext2, Ext3, ReiserFS), улучшенная работа с RAID-массивами, возможность настройки Wi-Fi и локальных сетей и многое другое.
Вообще, надо сказать, что использование данной программы построено на весьма интересном принципе. Дело в том, что вирусы работают только в среде операционных систем. В данном случае программа удаляет вирусы, поскольку они просто неактивны. К тому же, если данный компьютер подключен к локальной сети, угроза заражения остальных компьютеров отсутствует. Тем более, надо отдать должное специалистам Лаборатории Касперского, программа удаляет АБСОЛЮТНО все вирусы и еще неизвестные, но попавшие под подозрение потенциально опасные объекты. Сама программа построена на основе Gentoo Linux и Антивируса Касперского. Да и системные требования для нормального функционирования данного программного обеспечения по современным меркам довольно невысоки.