





 Рейтинг: 4.4/5.0 (1906 проголосовавших)
Рейтинг: 4.4/5.0 (1906 проголосовавших)Категория: Windows: Конверторы
Что делать, если надо распознать текст с картинки или сканированный текст, а подходящей программы на компьютере нет? Устанавливать специальный софт? Но это долго, и большинство их них платны.
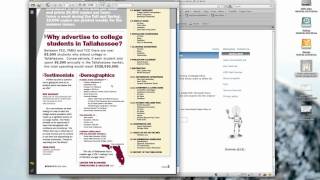
i2OCR (Optical Character Recognition) – 100% бесплатный онлайн сервис, который быстро распознает текст с любого изображения и позволит скачать его в виде файла. В качестве источника можно использовать страницы книг, факсы, рецепты, фотографии, скриншоты и пр.
Основные возможности i2OCRКак видим, возможности для бесплатного сервиса более чем впечатляющие и вполне достаточны для обычных нужд. Теперь рассмотрим как именно распознать текст с картинки при помощи i2OCR.
Как работать с сервисомВсё делается очень быстро в три простых этапа:
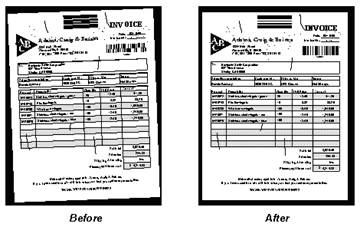
Для проверки качества работы сервиса я выбрал следующие изображение со сканированным текстом (качество шрифта не самое лучшее):
Вот такой результат я получил в итоге:
Всё распознано идеально, без ошибок кроме символа «№».
После того как текст будет распознан, появятся кнопки дополнительных опций:
Все ограничения сервиса носят лишь системный характер и состоят в следующем:
i2OCR не имеет ограничений на количество загружаемых файлов и на число скачиваний! Все возможности сервиса абсолютно бесплатны и доступны без регистрации!
При помощи сервиса i2OCR можно бесплатно распознать онлайн текст с картинки (скана, фото и пр.), сделать его перевод на другой язык, отредактировать, сохранить и скачать в одном из форматов (txt, doc, pdf, html). Всё делается быстро, четко и без установки на ПК дополнительных программ. Сервис однозначно должен быть в закладках у каждого!
P.S. Рекомендую также прочитать обзор двух лучших сервисов онлайн конвертирования речи в текст .






Распознать текст онлайн можно с помощью следующих ресурсов:
10.05.2013 Программы и сервисы
Часто ли вам нужно было распознать текст, а необходимой программы не было под рукой? Что делать, и как быть в такой ситуации? Выход есть – бесплатное распознавание текста онлайн сервисами. О некоторых из них и пойдет речь в данной статье.
Качество распознаваемого текста может отличаться у разных онлайн сервисов. Также, на качество влияет и исходный материал: фотография или сканированное изображение. Поэтому, выбор лучшего сервиса для распознания текста остается за вами. Мы лишь рассмотрим работу некоторых из них, отвечающих следующим критериям:
Google Docs – online офис, включающий в себя бесплатное оптическое распознавание текстов документов (OCR). Сервис может работать с различными форматами: JPEG, GIF и PNG, размер которых не превышает 2 МБ. Также он поддерживает многостраничные PDF-файлы (до 10 страниц).
Рассмотрим на примере, как распознать текст онлайн с картинки в Google Docs.
Чтобы работать в документах Гугл, вам необходимо иметь учётную запись в нем. Если у вас нет её – зарегистрируйте почтовый ящик в Google. Этого будет достаточно для доступа ко многим его сервисам.
В качестве примера для распознания текста возьмём картинку – скриншот части одной из предыдущих статей сайта, — её то мы и будем распознавать.
Итак, войдите в Google Docs (ссылка дана выше) под своим логином и паролем от почты Гугл.
В правом верхнем углу найдите иконку в виде шестерёнки (настройки), перейдите в «Настройки загрузки» и отметьте галочками все пункты в ней.
Затем нажмите на иконку загрузки – «стрелка вверх» (расположена слева) и выберите пункт «Файлы». В открывшемся окне укажите путь к картинке, которую вы хотите распознать и нажмите «Открыть». Прежде, чем изображение поместится в ваш «Google диск» вы увидите диалоговое окно с настройками загрузки.
Возможно, кто-то из вас спросил бы: а зачем мы тогда, на предыдущем шаге, настраивали загрузку, если снова появляется окно с её настройками? Всё дело в том, что теперь, помимо тех же настроек, что и в главном меню, предлагается выбор языка документа.
Если бы мы, ранее, не выполнили настройку загрузки, при добавлении файла не отобразилось бы это диалоговое окно, и распознавание текста мы бы не смогли выполнить.
Собственно, так выглядит диалоговое окно при добавлении нового файла (рисунок ниже).
Выберите язык документа, в данном случае это русский, и нажмите «Начать загрузку». Через некоторое время (зависит от размера загруженного файла) отобразится ваш документ.
Щелкните по нему правой кнопкой мыши и выберите «Открыть с помощью» — «Google документы».
В следующем окне откроется онлайн офис. Сверху отобразится изображение, а снизу распознанный текст.
Изображение можно выделить и удалить, оставив лишь текст. Чтобы сохранить документ на компьютер – перейдите в раздел меню «Файл» — «Скачать как» — выберите подходящий формат.
С одним сервисом распознавания текста онлайн разобрались, теперь перейдем к следующему.
ABBYY FineReader OnlineFineReader Online – сервис компании ABBYY. Он обладает вполне высоким качеством распознавания текстов, однако, это коммерческий продукт. Бесплатно распознать можно только 3 страницы текста, после чего предлагается купить данную услугу.
Перейдя по указанной выше ссылке, нажмите на FineReader Online. Затем откроется окно с возможностями этого сервиса по распознаванию текста онлайн. В качестве примера выберем один из них – «Извлекайте текст из цифровых фотографий».
Чтобы работать в сервисе – необходимо зарегистрироваться в нём.
Для распознавания текста с картинки, загрузите файл и выберите язык документа. Затем укажите формат сохранения результатов и жмите «Распознать».
Через некоторое время картинка будет распознана. В следующем окне можно сохранить документ, кликнув по нему мышью, или распознать следующий файл.
На этом описание работы FineReader Online завершено. Если хотите – ознакомьтесь с другими его возможностями самостоятельно. Но помните, это условно бесплатный продукт, после нескольких распознанных документов его услуги станут платными.
Если вы ищите бесплатную альтернативу программе по распознаванию текста – присмотритесь к Google Docs. Хоть он и имеет весьма специфический интерфейс, разобраться в принципах его работы сможет каждый желающий.
 02.09.2013 | Автор: Ильдар Шакиров
02.09.2013 | Автор: Ильдар Шакиров
 Как известно, для распознавания текста (из картинок, или с pdf файлов), необходима специальная программа. Вы, наверное, знаете, что практически все нормальные программы по распознаванию текста являются коммерческими, а для тех, кто не любит платить или просто не имеет достаточно средств, необходим альтернативный вариант.
Как известно, для распознавания текста (из картинок, или с pdf файлов), необходима специальная программа. Вы, наверное, знаете, что практически все нормальные программы по распознаванию текста являются коммерческими, а для тех, кто не любит платить или просто не имеет достаточно средств, необходим альтернативный вариант.
Так вот, хочу предложить Вам хорошую замену платным программам, а именно, бесплатный онлайн сервис по распознаванию текста.
Многие из вас наверное, знают, а может и слышали, что одной из лучших программ в данной области является программа FineReader от компании ABBYY. Как известно, данная программа платная и стоит довольно дорого. Есть, конечно, и бесплатные аналоги, но распознают текст они довольно плохо и функционал у них очень ограничен.
Бывают такие случаи, когда необходимо распознать одну или две странички. Вы же не будете ради этого покупать платный продукт, который потом может больше вообще не пригодиться.
В таких случаях нам могут помочь онлайн сервисы распознавания текста. К сожалению, не все они бесплатные. У выше описанной программы FineReader тоже есть свой онлайн сервис, но он платный. После регистрации Вам разрешат бесплатно распознать только три страницы. А если вам нужно распознать только что отсканированный реферат из 30 страниц?
Но выход всегда можно найти!
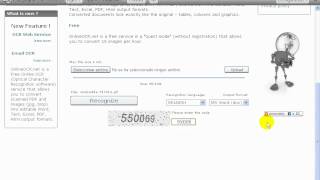
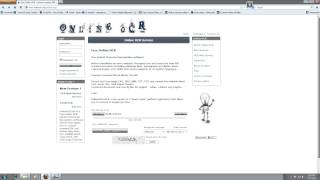
В интернете есть довольно хороший сервис для online распознавания текста под названием Free Online OCR.
Данный сервис поможет Вам бесплатно распознать текст из PDF файла или с картинки. Сервис поддерживает все основные форматы, а именно:
Конечный результат можно сохранить в разных основных форматах, таких как: DOC, TXT, PDF.
Сервис очень прост в использовании:
1) Сначала выбираем файл с текстом, который хотим распознать. Есть два варианта загрузки файла: с вашего компьютера или из Интернета. Во втором случае необходимо указать ссылку. Указываем язык распознавания.
2) Далее жмём кнопку «Preview». После этого изображение можно поворачивать и выделять нужную нам область для распознавания.
3) Как только всё готово, жмём кнопку «OCR» для распознавания или открываем другой файл.
4) После распознавания готовый текст появится внизу. Сохраняем его в нужном нам формате, нажав кнопу «Download» .
Воспользоваться сервисом можно перейдя по этой ссылке Free Online OCR
***********************************************************************************************************
Большой выбор маршрутизаторов. Mikrotik rb2011 по доступной цене.
Хотите первым получать обзоры свежих статей этого блога!?
Подпишитесь на RSS рассылку.
Для того чтобы отредактировать информацию, полученную со сканера, необходимо применить технологию, которая получила название OCR, что в расшифровке и в переводе на русский означает «оптическое распознавание символов». Мы задались вопросом, а существуют ли надежные и качественные OCR-системы, доступные онлайн?
На сегодняшний день техника шагнула достаточно далеко, и для получения фотокопии изображения уже не нужно искать сканер, достаточно просто достать телефон с фотокамерой и «щелкнуть» нужные страницы изображения. А уж если есть под рукой мало-мальски приличная «фотомыльница», то получить изображение нужной четкости и разрешения и вовсе не составляет труда. К слову, это стало настолько очевидно, что многие библиотеки, видимо, не желая терять заработок на услуге ксерокопирования, стали запрещать использование любой фототехники в читальном зале. Так что, прогресс налицо.
В области же оптического распознавания текста, к сожалению, никаких революций за последние пять лет не случилось, хотя определенные изменения все-таки произошли. Например, ощутимо сдвинулся баланс от настольных систем распознавания к применению веб-сервисов. Нельзя сказать, что OCR-рынок ушел в онлайн, но изменение самой концепции использования компьютера, распространение мобильной техники, Интернета, «облачных» сервисов — все это диктует ситуации, когда пользователь оказывается перед фактом, что стационарного компьютера под рукой нет.
Но в случае крайней необходимости можно сфотографировать и попытаться «скормить» фотоснимок одному из OCR-онлайн-сервисов. Вероятнее всего, со временем такой путь будет становиться все популярнее, и поэтому мы решили отправиться на исследование онлайн-просторов в поисках хорошего сервиса распознавания отсканированного текста.
Мы не ставили перед собой задачу найти непременно бесплатный сервис, предполагая, что таких может просто не быть. Однако некоммерческие ресурсы данного типа все-таки нашлись. Имеются также условно бесплатные, в которых можно распознать несколько страниц «на пробу». В любом случае сервис должен поддерживать русский язык и не требовать никакой установки на компьютер: иногда это просто невозможно на служебных машинах.
Для пробы мы приготовили несколько материалов, с которых OCR-сервисам предстояло «вытянуть» текст. Первый файл был получен путем сканирования на недорогом домашнем планшетном сканере с большим разрешением и настройками «по умолчанию». Второй кадр был в виде страницы из PDF-файла с разрешением, близким к экранному. Третий, уже посложнее, был снят с помощью фотоаппарата со штатива и максимально хорошим освещением. И наконец, четвертый файл был снят смартфоном среднего уровня с камерой 3 Мпикс, с применением встроенной вспышки.
Качество последнего файла плохим как по разрешению, четкости, так и по геометрии изображения, зато ближе всего к полевым условиям. Снимки были сделаны с обычных страниц книги, с делового отчета и содержали кроме текста еще и несложную таблицу. Именно с таким, вполне реалистичным набором данных предстояло разобраться испытуемым.
«Документы Google»
Первым на старт вышел Google со своими документами (docs.google.com ). Не все знают, что помимо совместной работы над материалом сервис позволяет распознать документ, загруженный в виде изображения или PDF. Никаких особенных действий предпринимать не нужно, все получается автоматически. Однако размер файла ограничен 2 Мбайт, так что полноценный скан страницы книги отправить не удалось. Уменьшив размер, мы смогли «вытащить» редактируемый текст.
«Документы Google» легко распознали разворот страницы и справились с текстом. Качество работы можно оценить не выше, чем 4 балла из 5, потому что ни одного абзаца без ошибки не случилось. Однако это все же на порядок быстрее и легче, чем набирать текст с чистого листа.
Со сложными исходными файлами дело пошло хуже: качество распознавания упало до «тройки» по пятибалльной шкале и не вышло распознавание сложного форматирования и таблиц. Тем не менее удовлетворительный результат был зафиксирован, и ресурс вполне стоит взять на вооружение как действенный способ получить текст из PDF или картинки.
FineReader Online
Переходим к явному фавориту нашего тестирования. Компания Abbyy уже пару лет предлагает воспользоваться всей мощью своего OCR-механизма через веб-сервис (finereader.abbyyonline.com ). Отличия от настольной версии, конечно, имеются. Прежде всего — в количестве поддерживаемых языков («всего» 49 против почти 200 в профессиональной версии FineReader ), а также в отсутствии каких-либо дополнительных возможностей по обработке текста после распознавания.
Входным форматом может быть практически любой популярный графический формат или PDF без пароля, а выходным — DOC, XLS, ODT, TXT и PDF. Загружать можно документы размером до 30 Мбайт.
Как и ожидалось, сервис продемонстрировал отличную работу и очень хорошее качество распознавания на всех исходных изображениях. Даже на самой плохой картинке, снятой мобильным телефоном, FineReader Online узнал и направление текста (самостоятельно повернул картинку), и форматирование абзацев, и даже таблицу! Фактически даже при самом плохом «исходнике» исправить пришлось всего несколько ошибок.
За использование чудо-сервиса, однако, придется заплатить. Возможность сканирования покупается постранично, и за 100 стр. надо будет выложить 7 долл. Однако качество того стоит — чистые 5 из 5!
На очереди у нас иностранный сервис и проверка того, как он справляется с русским языком. OCRonline ( www.ocronline.com ) работает с 14 самыми популярными европейскими языками. Услуга предоставляется не бесплатно, но при регистрации начисляется пять бесплатных «пробных» страниц и, кроме того, каждый понедельник ваш баланс пополняется бесплатно до тех самых пяти страниц. Дополнительные пакеты можно купить по цене от 8 долл. за 100 стр. и дешевле, если заказывать оптом.
Сам процесс распознавания мало чем примечателен. На выходе в вашем распоряжении будет текст в формате DOC, TXT, PDF или RTF. А вот результаты получились любопытные. Качественные изображения с фотоаппарата и со сканера с высоким разрешением были распознаны идеально, фактически без единой ошибки. Твердая пятерка! С картинкой низкого качества также справились на ура, даже таблица никуда не пропала! Но помарок было предостаточно, так что отличным такое распознавание назвать нельзя. Но 4 из 5 — это очень хороший показатель. Обязательно стоит взять этот ресурс на заметку для срочных задач.
Следующий веб-инструмент распознавания текста расположился в русскоязычной доменной зоне по адресу www.onlineocr.ru. Он также не бесплатный, и для получения выходного материала в одном из шести популярных форматов нужно купить «кредиты», за которые и осуществляется распознавание текста. В деморежиме получится увидеть только первую пару абзацев текста и то лишь в виде текста без форматирования. Исходный файл может быть размером до 20 Мбайт.
Пробы показали, что этот сервис очень чувствителен к качеству оригинала. Изображение со сканера в полном разрешении позволило получить очень хороший текст, практически без ошибок. А вот работа со сложным исходником не удалась. Качество текста оставляет желать лучшего, и исправлять опечатки в нем может быть сложнее, чем напечатать текст самому.
Многообещающее слово free в названии сервиса заставила нас обратить внимание на адрес www.free-ocr.com. в котором обитает следующий претендент на звание лучшего онлайн-механизма OCR.
Качество результата не на высоте, к сожалению. Текст даже с качественного изображения получился малопригодным к использованию — уж очень много ошибок. А фотография с мобильного телефона и вовсе распозналась как набор непонятных малочитаемых символов. Зато бесплатно. Вероятно, для простых текстов этот сайт можно применять, но рекомендовать его язык не поворачивается.
Еще один русскоязычный OCR-сайт вы найдете по адресу www.scanonline.ru. Стартовые условия выглядят заманчиво — файл до 20 Мбайт, поддерживаются все популярные форматы изображений для распознавания, результаты работы будут высланы на указанный адрес электронной почты в виде текста, HTML или RTF. Ресурс владеет шестью языками.
Доступен бесплатный лимит на 5 Мбайт загружаемых изображений в день. Если нужно больше, то можно открыть доступ на сутки с помощью платной SMS по заявленной цене около 20 руб.
Качество распознавания хорошего исходного изображения можно оценить в 4 балла. Ошибок немного, скорость и качество распознавания на достойном уровне. А вот выявление текста на фотографии с телефона оказалось для данного ресурса непосильной задачей. Фактически полученный набор символов был малопригоден к дальнейшей работе. Таким образом, при его использовании нужно учитывать, что этот условно бесплатный сервис очень чувствителен к качеству изображения.
Ресурс New OCR ( www.newocr.com ) обещает совершенно бесплатное применение OCR-технологии к нашим отсканированным документам. И надо сказать, с неплохим функционалом — по своим возможностям данный сервис действительно неплох. Судите сами: 58 языков, два разных OCR-алгоритма на выбор, безлимитные загрузки без необходимости регистрации и бесплатно (!), все популярные форматы, в том числе многостраничные документы, и даже загрузки заархивированных файлов.
Для исходных изображений доступен целый букет сервисных функций. Во-первых, можно выбрать область распознаваемого текста, повернуть картинку, повысить контрастность и распознать текст колонками.
Распознанный текст можно скачать во всех популярных текстовых форматах, включая ODT, отправить для публикации в «Документы Google» или, например, отправить напрямую в переводчик Google.
А что же с качеством непосредственно OCR? С качественными исходными материалами new OCR справился хорошо. Ошибок минимум, и лишь некоторая неразбериха с форматированием заставляет поставить минус к заслуженной пятерке. Можно попробовать улучшить результат, выбирая между двумя механизмами распознавания.
А вот с некачественным исходным материалом разобраться этому сервису не удалось. По существу, ничего полезного из картинки с низким разрешением и недостаточной четкостью извлечь ему не удалось. Несмотря на это, ресурс нам понравился, и рекомендуем занести его в закладки.
Sciweavers: i2OCR
Для полноты картины приведем еще один сайт. Ничего сверхвыдающегося он не обещает, зато бесплатен и имеет красивый интерфейс, в чем вы сможете убедиться сами, заглянув на www. sciweavers.org/ free-online-ocr. Поддер живается 33 языка и все популярные графические форматы для исходного файла. Качество распознавания не назовешь выдающимся, но на хорошей фотографии текст определяется с минимумом ошибок и почти не требует корректировки. С плохими изображениями беда, и от получающегося набора символов никакого толка. Зато бесплатно — это раз, и сопровождается целой охапкой других полезных сервисов по решению каждодневных задач конвертирования цифровых данных — это два.
Оценка по «чтению»
После ознакомлениями со всеми этими системами можно сделать некоторые выводы. Во-первых, — и это хорошая новость! — онлайн-сервисы по распознаванию текста есть, и они неплохо работают. Многие даже бесплатны, что, признаемся, стало приятным сюрпризом.
Во-вторых, снова подтвердился тезис, что в распознавании текста полдела — это качество снимка. Большинство OCR провалили тест на обработку изображения, сделанного мобильным телефоном. При этом материалы со сканера или качественный фотоснимок были обработаны неплохо. Значит, в «полевых» условиях необходимо обеспечить максимум света и разрешения при съемке, что обычно все-таки недоступно смартфонам даже выше среднего уровня.
Некоторые сервисы тем не менее справились и с «трудными» случаями, так что именно их мы уверенно ставим в лидеры обзора. Прежде всего это FineReader Оnline. Из бесплатных же онлайн-распознавателей лучше других себя показал New OCR. Поэтому именно этим двум сервисам мы присудили значок «Hard'n'Soft рекомендует».
Распознать и перевести!
В современном открытом мире часто бывает, что необходимо срочно понять, о чем идет речь на листе бумаги или в PDF-документе. Проблема в том, что он может быть на иностранном языке. Значит, в пару к OCR-ресурсу нужно найти онлайн-переводчик.
Рассмотренный нами в обзоре бесплатный сайт New OCR сразу после распознавания предлагает передать документ в Google Translate (translate.google.com). Это один из самых известных онлайн-переводчиков, который оперирует десятками языковых пар, при этом обладает простым интерфейсом и не содержит строгих ограничений на длину переводимого текста, так что отсканированный документ удастся прочитать сразу.
От автоматического перевода чудес в части совершенства ждать не приходится, тем не менее качество перевода Google Translate считается хорошим, и обычно именно этот сайт используют в первую очередь.
Альтернативное решение — это онлайн-сервис www.trans-late.ru отечественной компании ПРОМТ. Но здесь установлен лимит в 3 тыс. символов для единовременного перевода. Так что разворот книги пришлось переводить в два приема.
Используя эти или другие сервисы онлайн-переводов после оптического распознавания, проблема восприятия содержания материала на незнакомом языке должна просто сойти на нет. Еще бы объединить все самые лучшие достижения, да в одном интерфейсе, да бесплатно.
Очень часто в нашей рутинной работе возникает необходимость распознать текст с картинки или pdf файла. Конечно, можно заставить себя набить текст ручками, но мы же существа ленивые и хотим по-максимуму автоматизировать повседневные задачи, к тому же это значительно экономит время.
С программами то же все не очень просто. Найти бесплатный программный продукт для распознавания текста достаточно сложно, а покупать тот же FineReader имеет смысл лишь в том случае, если объем документов большой и есть острая необходимость в срочности и скорости распознавания такого большого объема документов.
Однако, если распознаете вы раз в неделю небольшие документы, то Вам в помощь придут бесплатные онлайн-сервисы для распознавания текста с картинки или файлов PDF. Сегодня я сделаю небольшой обзор таких сервисов. Главными критериями при выборе были:
Увы, последний пункт пришлось опустить, так как парочка хороших сервисов все же потребует от вас регистрации. Надо так же понимать, что распознавание картинки в текст онлайн не заменит профессиональных настольных продуктов, так как имеют ряд ограничений как по весу документа, количеству листов в документе, формате на выходе и т.д. Данные онлайн инструменты рассчитаны на разовые небольшие объемы. Но хватит лирики, приступим.
Online OCR — Онлайн сервис распознавания текстаС первый сервисом Online OCR произошел, однако, конфуз. Во время обзора он попросту не работал. Зайдя на сайт, я увидел такую картину:
Надеюсь создатели скоро поправят данный сервис, ведь он реально был хорош, если не лучший. Очень хороший функционал и не требовал регистрации. Большой набор форматов на выходе позволял переводить картинки как в документы Word, Excel, rtf, pdf и другие. Насколько я помню ограничение было по объему документа в 20 мегабайт, что вполне хватало для работы.
Google DocsДля многих может стать открытие тот факт, что и документы гугл умеют преобразовывать картинки в текст. Но это и первый наш сервис, который потребует регистрации, но думаю сейчас и не встретить человека без аккаунта в Google.
Для распознавания картинки или пдфки в текст вам надо:
Качество распознавания текста с картинки у Гугл просто чудесное, конечно при условии, что картинка нормального читаемого качества. После распознавания картинки вы сможете ее скачать в любом популярном формате: Word, RTF, PDF. ODT или TXT.
А вот про ограничения я информацию не нашел. Раньше знаю было, что размер документа должен был быть не более 10 мб и не более 10 страниц в документа. Но вроде бы эти ограничения были сняты, хотя могу ошибаться. Но точно знаю, что Google Docs является одним из самых удобных способов онлайн распознавания картинки в текст.
ABBYY FineReader OnlineНу кто не слышал о самой популярной программе для распознавания текста — ABBYY FineReader? Да я уверен, что таких почти нет. А вот про его онлайн версию слышали не многие. А зря. Ведь зачем платить 5 тыс. рублей, если онлайн версия практически не уступает своей десктопной версии, да и ограничение в 100 мб делает его куда более привлекательным, чем конкуренты с куда более меньшим разрешенным объемом.
Единственное неудобство — придется зарегистрироваться. Процедура не сложная и не займет у вас и больше 2-х минут. А если у вас есть аккаунты в том же Гугл, Фейсбук или Майкрософт, то можете зайти с помощью их и даже регистрации не потребуется.
Что сказать о качестве распознавания? Это ABBYY и этим все сказано. Мое коммерческое предложение он распознал практически идеально, вплоть до правильной таблицы и всех списков. Да, шрифт не тот, но он у меня в документе специфический. Со стандартными шрифтами такой беды не будет.
Увы, но в сутки вам разрешается распознавать не более 10 листов. Если ваш дневной объем укладывается в этот лимит, то это определенно то, что вы ищите.
img2txt.comСколько наблюдаю за данным сервисом, он все никак не выйдет из стадии бета-тестирования. Однако если Вам нужно быстро распознать текст с картинки, то img2txt.com вам может в этом помочь. Картинка должна быть хорошего качества, ибо ошибок будет слишком много.
Увы, но даже при хорошем качестве картинки, сервис допускает ошибки при распознавании. Так что придется немного править текст, а это лишние телодвижения.
Это последний на сегодня наш обозреваемый пациент и первый англоязычный, хоть и не хотел их трогать. Тут все просто:
Жмем «Process».
Увы, но зарубежный пациент справился не лучше нашего img2txt. Очень много ошибок, буквы Л он распознает как символы /\ и так далее и тому подобное.
Пожалуй пришло время подводить итоги обзора сервисов по распознаванию картинок и файлов PDF онлайн. Как бы не старались независимые программисты, но соперничать с Google и ABBYY им не под силу, а те в свою очередь требуют регистрации и наличие аккаунта.
Хорошим им подспорьем был Online OCR, однако на момент обзора он не работал, надеюсь скоро его поправят. Ну а если вы хотите реально качество, то остановите свой выбор на Google Docs и ABBYY FineReader Online.
У меня все. Удачи.
Online OCR сервис распознавания текста позволяет:
Распознать
текст или символы с любого изображения (отсканированный документ, цифровая фотография или просто картинка в формате JPG, BMP, TIF и др.). OnlineOCR.ru обрабатывает также многостраничные документы TIFF и PDF.
Конвертировать
полученный в результате распознавания, текст в следующие выходные форматы: Adobe PDF, MS Word, Excel, Html, Rtf, Txt. Созданный файл будет в точности повторять структуру исходного документа (таблицы, колонки, шрифты и т.д.)
файлы с результатом распознавания в вашем виртуальном рабочем кабинете online, скачивать их на жесткий диск, редактировать, отправлять по почте и распечатывать на принтере
Распознавание картинки в текст
Конвертер онлайн
Онлайновый сервис распознавания текста из картинки
Неплохой сервис распознавания текста из картинки. Чтобы получить текстовый файл (выдается в html), вам нужно загрузить с компьютера изображение в формате jpg, tif, png. Также, можно загружать и более сложные форматы изображения форматов djvu, pdf.
Ограничение на размер картинки - 2мБ. Рекомендуемое разрешение исходного файла - 300 точек на дюйм. Распознаются помимо русского еще множество других языков.
Free Online OCR
Конвертер онлайн
Free Online OCR - распознавание текста из картинки
Бесплатный сервис распознавания картинок онлайн от компании NewOCR. Free Online OCR может распознавать текст из картинки и конвертировать картинку в текст. Поддерживаются свыше 29 языков, в т.ч русский, английский, французский, испанский, итальянский, турецкий, латвийский, украинский, польский и многие другие.
Для работы сервиса не требуется регистрации, нет лимита на количество загрузок файлов, загружаемая картинка должна быть размером не свыше 5 Мб. Конвертер работает с форматами JPEG, PNG, GIF, BMP, TIFF, PDF.
Конвертер онлайн
Распознавание текста онлайн
Бесплатная распознавалка текста (OCR) в режиме онлайн.Пользуясь этим сервисом,вы можете получить текст из картинки. Конвертер не требует регистрации, просто загружаете картинку и получаете текст.
Картинка не должна быть больше, чем 2Мб. Поддерживаются форматы JPG, GIF, TIFF BMP и PDF (только первая страница). Также, сущесвтует лимит на 10 картинок в час.
Сервис распознает множество языков - русский, украинский, английския, немецкий, французский, турецкий, большинство восточноевропейских языков.
SimpleOCR - это бесплатная OCR система для распознавания текстов со сканера или с рисунков.
По качеству работы он не уступает многим платным аналогам. Точность распознавания может достигать 99% - это очень высокий показатель для подобных систем. Эта версия SimpleOCR работает с документами только на английском и французском языках, но в будущем появятся и словари на других языках.Среди прочих возможностей SimpleOCR можно отметить следующие:
* большой словарь, насчитывающий около 120 тысяч слов
* удаление пятен и "шумов" с документов
* сохранение форматирования шрифтов - подчеркивание, жирный, курсив
* захватывание фотографий из текста
 Перед каждым кто работает с текстами, да и перед обычными пользователями нередко встаёт необходимость распознать текст с картинки, фотографии, из книги, напечатанный на сканированном документе и прочее. Существуют программы, которые могут распознавать текст, но, во-первых, большинство из них платные, а, во-вторых, для работы такую программу надо устанавливать на компьютер.
Перед каждым кто работает с текстами, да и перед обычными пользователями нередко встаёт необходимость распознать текст с картинки, фотографии, из книги, напечатанный на сканированном документе и прочее. Существуют программы, которые могут распознавать текст, но, во-первых, большинство из них платные, а, во-вторых, для работы такую программу надо устанавливать на компьютер.
А что делать тем, у кого нет постоянной потребности в распознавании или если такая необходимость она возникла разово и достаточно неожиданно или не хочется держать лишний, редко используемый софт. В этом случае помогут сервисы распознавания текста которых в интернете много.
Эти проблемы отлично решат сервисы, способные распознать текст онлайн. Причем каждый такой сервис распознает текст бесплатно (существуют и те, которые делают это за символические суммы). Их не так мало в интернете, каждый отличается своими положительными или отрицательными сторонами, но в данной статье мы рассмотрим только те из них, которые удовлетворяют условиям:
Каким сервисом пользоваться выбираете вы сами. Многие из них отличаются по качеству распознавания и другим параметрам. С другой стороны многое зависит от качества распознаваемого документа.
Сервисы распознавания текстов: Начнем с Drive Google, его можно найти в Google Документах. Он нам подходит прежде всего из-за того, что полностью русифицирован. Не слишком удобно то, что для тех, у кого собственного аккаунта в Google нет, потребуется регистрация. Обойдутся без этого те, у кого на blogspot уже существует свой блог. Кроме русского распознает тексты еще на 28 языках. Поддерживаются документы до 10 Mb и форматы JPG, PNG, GIF, PDF (в PDF распознаются первые 10 страниц). Файлы, в которых текст сохраняются: DOC, PDF, TXT, PRT, ODT.
Начнем с Drive Google, его можно найти в Google Документах. Он нам подходит прежде всего из-за того, что полностью русифицирован. Не слишком удобно то, что для тех, у кого собственного аккаунта в Google нет, потребуется регистрация. Обойдутся без этого те, у кого на blogspot уже существует свой блог. Кроме русского распознает тексты еще на 28 языках. Поддерживаются документы до 10 Mb и форматы JPG, PNG, GIF, PDF (в PDF распознаются первые 10 страниц). Файлы, в которых текст сохраняются: DOC, PDF, TXT, PRT, ODT.