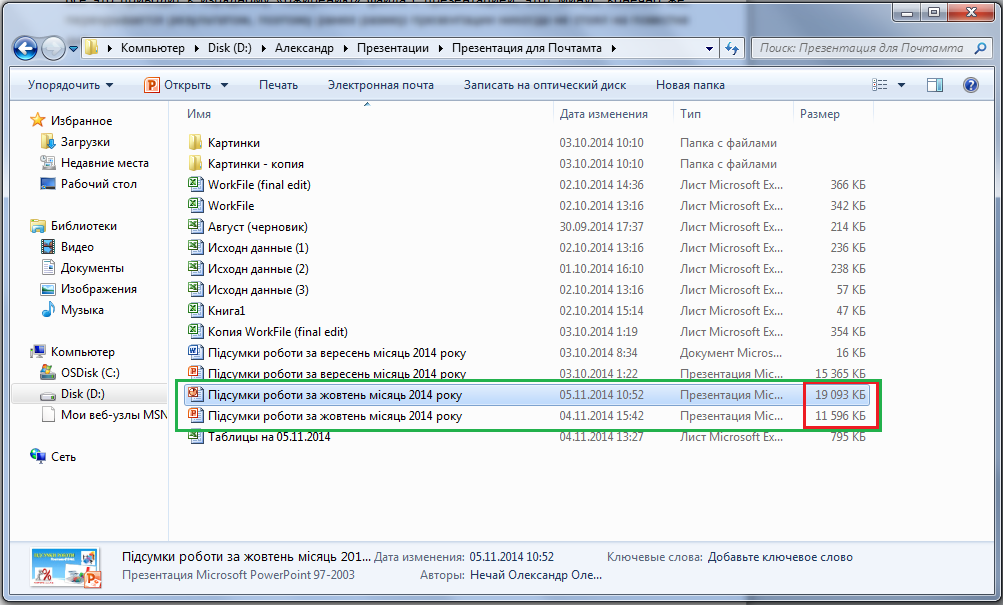







 Рейтинг: 4.2/5.0 (1611 проголосовавших)
Рейтинг: 4.2/5.0 (1611 проголосовавших)Категория: Windows: Диагностика, тесты
Тесты проводились на следующем стенде:
Для тестов мы подобрали процессоры и видеокарты от одних производителей, соответственно, Intel и NVIDIA. Это было сделано с целью меньшего влияния архитектурных особенностей комплектующих на общую картину. Были собраны две конфигурации: Core 2 Duo E8400 + GeForce 9800 GT 512 Мбайт и Pentium E6300 + GeForce GTX 260 896 Мбайт. Как видно, одна система с мощным процессором и слабой видеокартой, а вторая наоборот - со слабым CPU и мощным GPU.
Все игры тестировались в разрешениях 1280х1024 и 1680х1050. В разрешении 1280х1024 система на базе Core 2 Duo E8400 и GeForce 9800 GT 512 Мбайт получит преимущество за счет мощного процессора. В более высоком разрешении - 1680х1050 - нагрузка в основном ляжет на видеокарту, поэтому вследствие возросшей роли графического адаптера майку лидера, предположительно, должна получить конфигурация с Pentium E6300 + GeForce GTX 260 896 Мбайт.
В недавней статье "Сводное тестирование процессоров Core 2 Quad Q9550/Q9400/Q8300, Core 2 Duo E8400/E7600 и Pentium E6500/E5400 в играх" было выявлено немало игр, в которых процессор оказывает значительное влияние на производительность компьютера даже в высоких разрешениях, поэтому особенно интересно, чем закончится сегодняшнее противостояние.
Мы не стали тестировать данные связки в разрешении 1920х1080, так как у видеокарты GeForce 9800 GT 512 Мбайт по естественным причинам в нем могли возникнуть проблемы с производительностью. Это можно посчитать существенным недостатком, но цель нашего исследования - не определить победителя в сегодняшнем противостоянии двух разных систем, а выявить основные тенденции и ответить на вопрос, что важнее при выборе "железа" для игр: процессор или видеокарта.
В следующих играх использовались средства измерения быстродействия (бенчмарк):Во всех играх замерялись минимальные и средние значения FPS.
В тестах, в которых отсутствовала возможность замера минимального FPS. это значение измерялось утилитой FRAPS.
VSync при проведении тестов был отключен.
Чтобы избежать ошибок и минимизировать погрешности измерений, все тесты производились по три раза. При вычислении среднего FPS за итоговый результат бралось среднеарифметическое значение результатов всех прогонов. В качестве минимального FPS выбиралось минимальное значение показателя по результатам трех прогонов.
Тестирование конфигураций проводилось в двух режимах работы:Перейдем непосредственно к тестам.



















Сергей Пахомов
Как-то раз довелось мне побеседовать на компьютерном рынке с техническим директором одной из многочисленных компаний, занимающихся продажами ноутбуков. Этот «специалист» пытался с пеной у рта объяснить, какая именно конфигурация ноутбука мне нужна. Главный посыл его монолога заключался в том, что время центральных процессоров (CPU) закончилось, и сейчас все приложения активно используют вычисления на графическом процессоре (GPU), а потому производительность ноутбука целиком и полностью зависит от графического процессора, а на CPU можно не обращать никакого внимания. Поняв, что спорить и пытаться вразумить этого технического директора абсолютно бессмысленно, я не стал терять времени зря и купил нужный мне ноутбук в другом павильоне. Однако сам факт такой вопиющей некомпетентности продавца меня поразил. Было бы понятно, если бы он пытался обмануть меня, как покупателя. Отнюдь. Он искренне верил в то, что говорил. Да, видимо, маркетологи в NVIDIA и AMD не зря едят свой хлеб, и им-таки удалось внушить некоторым пользователям идею о доминирующей роли графического процессора в современном компьютере.
Тот факт, что сегодня вычисления на графическом процессоре (GPU) становятся всё более популярными, не вызывает сомнения. Однако это отнюдь не принижает роли центрального процессора. Более того, если говорить о подавляющем большинстве пользовательских приложений, то на сегодняшний день их производительность целиком и полностью зависит от производительности CPU. То есть подавляющее количество пользовательских приложений не используют вычисления на GPU.
Вообще, вычисления на GPU главным образом выполняются на специализированных HPC-системах для научных расчетов. А вот пользовательские приложения, в которых применяются вычисления на GPU, можно пересчитать по пальцам. При этом следует сразу же оговориться, что термин «вычисления на GPU» в данном случае не вполне корректен и может ввести в заблуждение. Дело в том, что если приложение использует вычисление на GPU, то это вовсе не означает, что центральный процессор бездействует. Вычисление на GPU не предполагает переноса нагрузки с центрального процессора на графический. Как правило, центральный процессор при этом остается загруженным, а использование графического процессора, наряду с центральным, позволяет повысить производительность, то есть сократить время выполнения задачи. Причем сам GPU здесь выступает в роли своеобразного сопроцессора для CPU, но ни в коем случае не заменяет его полностью.
Чтобы разобраться, почему вычисления на GPU не являются эдакой панацеей и почему некорректно утверждать, что их вычислительные возможности превосходят возможности CPU, необходимо уяснить разницу между центральным и графическим процессором.
Различия в архитектурах GPU и CPUЯдра CPU проектируются для выполнения одного потока последовательных инструкций с максимальной производительностью, а GPU — для быстрого исполнения очень большого числа параллельно выполняемых потоков инструкций. В этом и заключается принципиальное отличие графических процессоров от центральных. CPU представляет собой универсальный процессор или процессор общего назначения, оптимизированный для достижения высокой производительности единственного потока команд, обрабатывающего и целые числа, и числа с плавающей точкой. При этом доступ к памяти с данными и инструкциями происходит преимущественно случайным образом.
Для повышения производительности CPU они проектируются так, чтобы выполнять как можно больше инструкций параллельно. Например для этого в ядрах процессора используется блок внеочередного выполнения команд, позволяющий переупорядочивать инструкции не в порядке их поступления, что позволяет поднять уровень параллелизма реализации инструкций на уровне одного потока. Тем не менее это все равно не позволяет осуществить параллельное выполнение большого числа инструкций, да и накладные расходы на распараллеливание инструкций внутри ядра процессора оказываются очень существенными. Именно поэтому процессоры общего назначения имеют не очень большое количество исполнительных блоков.
Графический процессор устроен принципиально иначе. Он изначально проектировался для выполнения огромного количества параллельных потоков команд. Причем эти потоки команд распараллелены изначально, и никаких накладных расходов на распараллеливание инструкций в графическом процессоре просто нет. Графический процессор предназначен для визуализации изображения. Если говорить упрощенно, то на входе он принимает группу полигонов, проводит все необходимые операции и на выходе выдает пикселы. Обработка полигонов и пикселов независима, их можно обрабатывать параллельно, отдельно друг от друга. Поэтому из-за изначально параллельной организации работы в GPU используется большое количество исполнительных блоков, которые легко загрузить, в отличие от последовательного потока инструкций для CPU.
Графические и центральные процессоры различаются и по принципам доступа к памяти. В GPU доступ к памяти легко предсказуем: если из памяти читается тексель текстуры, то через некоторое время придет срок и для соседних текселей. При записи происходит то же самое: если какойто пиксел записывается во фреймбуфер, то через несколько тактов будет записываться пиксел, расположенный рядом с ним. Поэтому GPU, в отличие от CPU, просто не нужна кэшпамять большого размера, а для текстур требуются лишь несколько килобайт. Различен и принцип работы с памятью у GPU и CPU. Так, все современные GPU имеют несколько контроллеров памяти, да и сама графическая память более быстрая, поэтому графические процессоры имеют гораздо бо льшую пропускную способность памяти, по сравнению с универсальными процессорами, что также весьма важно для параллельных расчетов, оперирующих огромными потоками данных.
В универсальных процессорах бо льшую часть площади кристалла занимают различные буферы команд и данных, блоки декодирования, блоки аппаратного предсказания ветвления, блоки переупорядочения команд и кэшпамять первого, второго и третьего уровней. Все эти аппаратные блоки нужны для ускорения исполнения немногочисленных потоков команд за счет их распараллеливания на уровне ядра процессора.
Сами же исполнительные блоки занимают в универсальном процессоре относительно немного места.
В графическом процессоре, наоборот, основную площадь занимают именно многочисленные исполнительные блоки, что позволяет ему одновременно обрабатывать несколько тысяч потоков команд.
Можно сказать, что, в отличие от современных CPU, графические процессоры предназначены для параллельных вычислений с большим количеством арифметических операций.
Использовать вычислительную мощь графических процессоров для неграфических задач возможно, но только в том случае, если решаемая задача допускает возможность распараллеливания алгоритмов на сотни исполнительных блоков, имеющихся в GPU. В частности, выполнение расчетов на GPU показывает отличные результаты в случае, когда одна и та же последовательность математических операций применяется к большому объему данных. При этом лучшие результаты достигаются, если отношение числа арифметических инструкций к числу обращений к памяти достаточно велико. Эта операция предъявляет меньшие требования к управлению исполнением и не нуждается в использовании емкой кэшпамяти.
Можно привести множество примеров научных расчетов, где преимущество GPU над CPU в плане эффективности вычислений неоспоримо. Так, множество научных приложений по молекулярному моделированию, газовой динамике, динамике жидкостей и прочему отлично приспособлено для расчетов на GPU.
Итак, если алгоритм решения задачи может быть распараллелен на тысячи отдельных потоков, то эффективность решения такой задачи с применением GPU может быть выше, чем ее решение средствами только процессора общего назначения. Однако нельзя так просто взять и перенести решение какойто задачи с CPU на GPU, хотя бы просто потому, что CPU и GPU используют разные команды. То есть когда программа пишется под решение на CPU, то применяется набор команд х86 (или набор команд, совместимый с конкретной архитектурой процессора), а вот для графического процессора используются уже совсем другие наборы команд, которые опять-таки учитывают его архитектуру и возможности. При разработке современных 3D-игр применяются API DirectX и OрenGL, позволяющие программистам работать с шейдерами и текстурами. Однако использование API DirectX и OрenGL для неграфических вычислений на графическом процессоре — это не лучший вариант.
NVIDIA CUDA и AMD APPИменно поэтому, когда стали предприниматься первые попытки реализовать неграфические вычисления на GPU (General Purpose GPU, GPGPU), возник компилятор BrookGPU. До его создания разработчикам приходилось получать доступ к ресурсам видеокарты через графические API OpenGL или Direct3D, что значительно усложняло процесс программирования, так как требовало специфических знаний — приходилось изучать принципы работы с 3D-объектами (шейдерами, текстурами и т.п.). Это явилось причиной весьма ограниченного применения GPGPU в программных продуктах. BrookGPU стал своеобразным «переводчиком». Эти потоковые расширения к языку Си скрывали от программистов трехмерный API и при его использовании надобность в знаниях 3D-программирования практически отпала. Вычислительные мощности видеокарт стали доступны программистам в виде дополнительного сопроцессора для параллельных расчетов. Компилятор BrookGPU обрабатывал файл с кодом Cи и расширениями, выстраивая код, привязанный к библиотеке с поддержкой DirectX или OpenGL.
Во многом благодаря BrookGPU, компании NVIDIA и ATI (ныне AMD) обратили внимание на зарождающуюся технологию вычислений общего назначения на графических процессорах и начали разработку собственных реализаций, обеспечивающих прямой и более прозрачный доступ к вычислительным блокам 3D-ускорителей.
В результате компания NVIDIA разработала программно-аппаратную архитектуру параллельных вычислений CUDA (Compute Unified Device Architecture). Архитектура CUDA позволяет реализовать неграфические вычисления на графических процессорах NVIDIA.
Релиз публичной бета-версии CUDA SDK состоялся в феврале 2007 года. В основе API CUDA лежит упрощенный диалект языка Си. Архитектура CUDA SDK обеспечивает программистам реализацию алгоритмов, выполнимых на графических процессорах NVIDIA, и включение специальных функций в текст программы на Cи. Для успешной трансляции кода на этом языке в состав CUDA SDK входит собственный Сикомпилятор командной строки nvcc компании NVIDIA.
CUDA — это кроссплатформенное программное обеспечение для таких операционных систем, как Linux, Mac OS X и Windows.
Компания AMD (ATI) также разработала свою версию технологии GPGPU, которая ранее называлась AТI Stream, а теперь — AMD Accelerated Parallel Processing (APP). Основу AMD APP составляет открытый индустриальный стандарт OpenCL (Open Computing Language). Стандарт OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является реализацией техники GPGPU. Это полностью открытый стандарт, его использование не облагается лицензионными отчислениями. Отметим, что AMD APP и NVIDIA CUDA несовместимы друг с другом, тем не менее, последняя версия NVIDIA CUDA поддерживает и OpenCL.
Тестирование GPGPU в видеоконвертерах
Итак, мы выяснили, что для реализации GPGPU на графических процессорах NVIDIA предназначена технология CUDA, а на графических процессорах AMD — API APP. Как уже отмечалось, использование неграфических вычислений на GPU целесообразно только в том случае, если решаемая задача может быть распараллелена на множество потоков. Однако большинство пользовательских приложений не удовлетворяют этому критерию. Впрочем, есть и некоторые исключения. К примеру, большинство современных видеоконвертеров поддерживают возможность использования вычислений на графических процессорах NVIDIA и AMD.
Для того чтобы выяснить, насколько эффективно используются вычисления на GPU в пользовательских видеоконвертерах, мы отобрали три популярных решения: Xilisoft Video Converter Ultimate 7.7.2, Wondershare Video Converter Ultimate 6.0.3.2 и Movavi Video Converter 10.2.1. Эти конвертеры поддерживают возможность использования графических процессоров NVIDIA и AMD, причем в настройках видеоконвертеров можно отключить эту возможность, что позволяет оценить эффективность применения GPU.
Для видеоконвертирования мы применяли три различных видеоролика.
Первый видеоролик имел длительность 3 мин 35 с и размер 1,05 Гбайт. Он был записан в формате хранения данных (контейнер) mkv и имел следующие характеристики:
Второй видеоролик имел длительность 4 мин 25 с и размер 1,98 Гбайт. Он был записан в формате хранения данных (контейнер) MPG и имел следующие характеристики:
Третий видеоролик имел длительность 3 мин 47 с и размер 197 Мбайт. Он был записан в формате хранения данных (контейнер) MOV и имел следующие характеристики:
Все три тестовых видеоролика конвертировались с использованием видеоконвертеров в формат хранения данных MP4 (кодек H.264) для просмотра на планшете iPad 2. Разрешение выходного видеофайла составляло 1280*um*720.
Отметим, что мы не стали использовать абсолютно одинаковые настройки конвертирования во всех трех конвертерах. Именно поэтому по времени конвертирования некорректно сравнивать эффективность самих видеоконвертеров. Так, в видеоконвертере Xilisoft Video Converter Ultimate 7.7.2 для конвертирования применялся пресет iPad 2 — H.264 HD Video. В этом пресете используются следующие настройки кодирования:
В видеоконвертере Wondershare Video Converter Ultimate 6.0.3.2 использовался пресет iPad 2 cо следующими дополнительными настройками:
В конвертере Movavi Video Converter 10.2.1 применялся пресет iPad (1280*um*720, H.264) (*.mp4) со следующими дополнительными настройками:
Конвертирование каждого исходного видеоролика проводилось по пять раз на каждом из видеоконвертеров, причем с использованием как графического процессора, так и только CPU. После каждого конвертирования компьютер перезагружался.
В итоге, каждый видеоролик конвертировался десять раз в каждом видеоконвертере. Для автоматизации этой рутинной работы была написана специальная утилита с графическим интерфейсом, позволяющая полностью автоматизировать процесс тестирования.
Конфигурация стенда для тестированияСтенд для тестирования имел следующую конфигурацию:
На стенде устанавливалась операционная система Windows 7 Ultimate (64-bit).
Первоначально мы провели тестирование в штатном режиме работы процессора и всех остальных компонентов системы. При этом процессор Intel Core i7-3770K работал на штатной частоте 3,5 ГГц c активированным режимом Turbo Boost (максимальная частота процессора в режиме Turbo Boost составляет 3,9 ГГц).
Затем мы повторили процесс тестирования, но при разгоне процессора до фиксированной частоты 4,5 ГГц (без использования режима Turbo Boost). Это позволило выявить зависимость скорости конвертирования от частоты процессора (CPU).
На следующем этапе тестирования мы вернулись к штатным настройкам процессора и повторили тестирование уже с другими видеокартами:
Таким образом, видеоконвертирование проводилось на четырех видеокартах различной архитектуры.
Старшая видеокарта NVIDIA GeForce 660Ti основана на одноименном графическом процессоре с кодовым обозначением GK104 (архитектура Kepler), производимом по 28-нм техпроцессу. Этот графический процессор содержит 3,54 млрд транзисторов, а площадь кристалла составляет 294 мм2.
Напомним, что графический процессор GK104 включает четыре кластера графической обработки (Graphics Processing Clusters, GPC). Кластеры GPC являются независимыми устройствами в составе процессора и способны работать как отдельные устройства, поскольку обладают всеми необходимыми ресурсами: растеризаторами, геометрическими движками и текстурными модулями.
Каждый такой кластер имеет два потоковых мультипроцессора SMX (Streaming Multiprocessor), но в процессоре GK104 в одном из кластеров один мультипроцессор заблокирован, поэтому всего имеется семь мультипроцессоров SMX.
Каждый потоковый мультипроцессор SMX содержит 192 потоковых вычислительных ядра (ядра CUDA), поэтому в совокупности процессор GK104 насчитывает 1344 вычислительных ядра CUDA. Кроме того, каждый SMX-мультипроцессор содержит 16 текстурных модулей (TMU), 32 блока специальных функций (Special Function Units, SFU), 32 блока загрузки и хранения (Load-Store Unit, LSU), движок PolyMorph и многое другое.
Видеокарта GeForce GTX 460 основана на графическом процессоре с кодовым обозначением GF104 на базе архитектуры Fermi. Этот процессор производится по 40-нм техпроцессу и содержит порядка 1,95 млрд транзисторов.
Графический процессор GF104 включает два кластера графической обработки GPC. Каждый из них имеет четыре потоковых мультипроцессора SM, но в процессоре GF104 в одном из кластеров один мультипроцессор заблокирован, поэтому существует всего семь мультипроцессоров SM.
Каждый потоковый мультипроцессор SM содержит 48 потоковых вычислительных ядра (ядра CUDA), поэтому в совокупности процессор GK104 насчитывает 336 вычислительных ядра CUDA. Кроме того, каждый SM-мультипроцессор содержит восемь текстурных модулей (TMU), восемь блоков специальных функций (Special Function Units, SFU), 16 блоков загрузки и хранения (Load-Store Unit, LSU), движок PolyMorph и многое другое.
Графический процессор GeForce GTX 280 относится ко второму поколению унифицированной архитектуры графических процессоров NVIDIA и по своей архитектуре сильно отличается от архитектуры Fermi и Kepler.
Графический процессор GeForce GTX 280 состоит из кластеров обработки текстур (Texture Processing Clusters, TPC), которые, хоть и похожи, но в то же время сильно отличаются от кластеров графической обработки GPC в архитектурах Fermi и Kepler. Всего таких кластеров в процессоре GeForce GTX 280 насчитывается десять. Каждый TPC-кластер включает три потоковых мультипроцессора SM и восемь блоков текстурной выборки и фильтрации (TMU). Каждый мультипроцессор состоит из восьми потоковых процессоров (SP). Мультипроцессоры также содержат блоки выборки и фильтрации текстурных данных, используемых как в графических, так и в некоторых расчетных задачах.
Таким образом, в одном TPC-кластере — 24 потоковых процессора, а в графическом процессоре GeForce GTX 280 их уже 240.
Сводные характеристики используемых в тестировании видеокарт на графических процессорах NVIDIA представлены в таблице .
В приведенной таблице нет видеокарты AMD Radeon HD6850, что вполне естественно, поскольку по техническим характеристикам ее трудно сравнивать с видеокартами NVIDIA. А потому рассмотрим ее отдельно.
Графический процессор AMD Radeon HD6850, имеющий кодовое наименование Barts, изготовляется по 40-нм техпроцессу и содержит 1,7 млрд транзисторов.
Архитектура процессора AMD Radeon HD6850 представляет собой унифицированную архитектуру с массивом общих процессоров для потоковой обработки многочисленных видов данных.
Процессор AMD Radeon HD6850 состоит из 12 SIMD-ядер, каждое из которых содержит по 16 блоков суперскалярных потоковых процессоров и четыре текстурных блока. Каждый суперскалярный потоковый процессор содержит пять универсальных потоковых процессоров. Таким образом, всего в графическом процессоре AMD Radeon HD6850 насчитывается 12*um*16*um*5=960 универсальных потоковых процессоров.
Частота графического процессора видеокарты AMD Radeon HD6850 составляет 775 МГц, а эффективная частота памяти GDDR5 — 4000 МГц. При этом объем памяти составляет 1024 Мбайт.
Результаты тестированияИтак, давайте обратимся к результатам тестирования. Начнем с первого теста, когда используется видеокарта NVIDIA GeForce GTX 660Ti и штатный режим работы процессора Intel Core i7-3770K.
На рис. 1-3 показаны результаты конвертирования трех тестовых видеороликов тремя конвертерами в режимах с применением графического процессора и без.
Как видно по результатам тестирования, эффект от использования графического процессора налицо. Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 в случае применения графического процессора время конвертирования сокращается на 14, 9 и 19% для первого, второго и третьего видеоролика соответственно.
Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 использование графического процессора позволяет сократить время конвертирования на 10, 13 и 23% для первого, второго и третьего видеоролика соответственно.
Но более всех от применения графического процессора выигрывает конвертер Movavi Video Converter 10.2.1. Для первого, второго и третьего видеоролика сокращение времени конвертирования составляет 64, 81 и 41% соответственно.
Понятно, что выигрыш от использования графического процессора зависит и от исходного видеоролика, и от настроек видеоконвертирования, что, собственно, и демонстрируют полученные нами результаты.
Теперь посмотрим, каков будет выигрыш по времени конвертирования при разгоне процессора Intel Core i7-3770K до частоты 4,5 ГГц. Если считать, что в штатном режиме все ядра процессора при конвертировании загружены и в режиме Turbo Boost работают на частоте 3,7 ГГц, то увеличение частоты до 4,5 ГГц соответствует разгону по частоте на 22%.
На рис. 4-6 показаны результаты конвертирования трех тестовых видеороликов при разгоне процессора в режимах с использованием графического процессора и без. В данном случае применение графического процессора позволяет получить выигрыш по времени конвертирования.
Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 в случае применения графического процессора время конвертирования сокращается на 15, 9 и 20% для первого, второго и третьего видеоролика соответственно.
Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 использование графического процессора позволяет сократить время конвертирования на 10, 10 и 20% для первого, второго и третьего видеоролика соответственно.
Для конвертера Movavi Video Converter 10.2.1 применение графического процессора позволяет сократить время конвертирования на 59, 81 и 40% соответственно.
Естественно, интересно посмотреть, как разгон процессора позволяет уменьшить время конвертирования при использовании графического процессора и без него.
На рис. 7-9 представлены результаты сравнения времени конвертирования видеороликов без использования графического процессора в штатном режиме работы процессора и в режиме разгона. Поскольку в данном случае конвертирование проводится только средствами CPU без вычислений на GPU, очевидно, что увеличение тактовой частоты работы процессора приводит к сокращению времени конвертирования (увеличению скорости конвертирования). Столь же очевидно, что сокращение скорости конвертирования должно быть примерно одинаково для всех тестовых видеороликов. Так, для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 при разгоне процессора время конвертирования сокращается на 9, 11 и 9% для первого, второго и третьего видеоролика соответственно. Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 время конвертирования сокращается на 9, 9 и 10% для первого, второго и третьего видеоролика соответственно. Ну а для видеоконвертера Movavi Video Converter 10.2.1 время конвертирования сокращается на 13, 12 и 12% соответственно.
Таким образом, при разгоне процессора по частоте на 20% время конвертирования сокращается примерно на 10%.
Сравним время конвертирования видеороликов с использованием графического процессора в штатном режиме работы процессора и в режиме разгона (рис. 10-12).
Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 при разгоне процессора время конвертирования сокращается на 10, 10 и 9% для первого, второго и третьего видеоролика соответственно. Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 время конвертирования сокращается на 9, 6 и 5% для первого, второго и третьего видеоролика соответственно. Ну а для видеоконвертера Movavi Video Converter 10.2.1 время конвертирования сокращается на 0,2, 10 и 10% соответственно.
Как видим, для конвертеров Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32 сокращение времени конвертирования при разгоне процессора примерно одинаково как при использовании графического процессора, так и без его применения, что логично, поскольку эти конвертеры не очень эффективно используют вычисления на GPU. А вот для конвертера Movavi Video Converter 10.2.1, который эффективно использует вычисления на GPU, разгон процессора в режиме использования вычислений на GPU мало сказывается на сокращении времени конвертирования, что также понятно, поскольку в данном случае основная нагрузка ложится на графический процессор.
Теперь посмотрим результаты тестирования с различными видеокартами.
Казалось бы, чем мощнее видеокарта и чем больше в графическом процессоре ядер CUDA (или универсальных потоковых процессоров для видеокарт AMD), тем эффективнее должно быть видеоконвертирование в случае применения графического процессора. Но на практике получается не совсем так.
Что касается видеокарт на графических процессорах NVIDIA, то ситуация следующая. При использовании конвертеров Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32 время конвертирования практически никак не зависит от типа используемой видеокарты. То есть для видеокарт NVIDIA GeForce GTX 660Ti, NVIDIA GeForce GTX 460 и NVIDIA GeForce GTX 280 в режиме использования вычислений на GPU время конвертирования получается одно и то же (рис. 13-15).
GPU (графический процессор) - высокотехнологическое устройство отвечающее за обработку графики в компьютерах, ноутбуках, мобильных телефонах. Современные GPU обладают специализированной конвейерной архитектурой, благодаря чему очень эффективно обрабатывают графическую информацию в сравнении с типичным центральным процессором. Может применяться как в составе дискретной видеокарты, так и в интегрированных решениях (встроенных в северный мост либо в гибридный процессор).
Основные отличия GPU от CPU:
Высокая скорость и мощность процессоров GPU на данное время объясняется особенностями архитектуры построения. Если современные CPU состоят из 2-6 ядер, то GPU считается многоядерной структурой, использующей сразу до сотни ядер. CPU предполагает обработку информации последовательно, а GPU рассчитан на многопотоковую параллельную работу с массивом информации.
 Zets 22 Май 2006
Zets 22 Май 2006
эверест показывает на нем
60градусов и
70градусов под нагрузкой, эт нормально?
 Loco. 22 Май 2006
Loco. 22 Май 2006
 DVDshnik 23 Май 2006
ERROR 23 Май 2006
DVDshnik 23 Май 2006
DVDshnik 23 Май 2006
ERROR 23 Май 2006
DVDshnik 23 Май 2006
Термопара и термодиод - две большие разницы, однако.
Zets 23 Май 2006
Видяха N6600, там помимо кулера есть еще радиатор(не знаю что он охлаждает), он бывает достаточно горяч. На старой материнке это давало глюки палигонов в играх, на новой вроде нечего. Хотел сделать возврат денег, но сволочи из компьютерной фирмы сказали что она рабочая и характеристики в норме, а то что греется и может сгореть их не волнует..
50 (под нагрузкой доходит,как я понял по перезагружающемуся компу, и до 70).
Свойства датчика:
Тип датчика Winbond W83627HF (ISA 290h)
Тип датчика ГП Fintek F75375S (NV-I2C 2Eh)
Системная плата / Видеоадаптер Epox 4BDA / 4BDM / 4BEA / 4G4A / 4GEA / 4PDA / 4PEA / 4PGA Series / Asus N6600
15.11.2007 | Refouler | обсудить (6)
Статья прислана на конкурс Летний АвторRUN!
Видеокарта является неотъемлемой частью сегодняшнего компьютера, и трудно представить, что было время, когда без нее можно было спокойно обойтись. С тех пор прошло довольно много времени, и сейчас "видеокарта" приближается к некому рубежу, за которым - неизвестность. В статье мы постараемся вкратце проследить эволюцию видеокарты. Сразу отмечу: читать придется много, даже очень много, и при этом без некоторого умственного напряжения не обойтись, так что если это вас не смущает, и вы жаждете новых знаний, можете спокойно приступать к чтению. Особенно рекомендовано тем, кто в детстве любил разбирать игрушки - затем чтобы глянуть, что же там внутри.
Поначалу я намеревался дать подробное описание всех перипетий, связанных с видеокартами, но когда стало понятно, что по теме можно писать чуть не вечно, было принято решение "взять в руки ножницы и скотч и немного поработать". Но девиз остался прежним: "все что вы хотели знать, но боялись спросить".
Для начала мы окунемся в историю и заодно освежим в памяти теорию, термины и определения.
Для того чтобы создать любой трехмерный объект (из совокупного числа которых мы получаем трехмерную сцену), нам нужно задать ему вершины, определяющие ключевые точки, и полигоны, которые образованы линиями, соединяющими вершины. (Как известно, графические ускорители работают с полигонной графикой, а это означает, что любой объект состоит из набора плоских многоугольников. Последние, в свою очередь, практически всегда разбиваются на простейшие треугольники. С такими фигурами очень удобно и, главное, просто работать. К тому же для всех алгоритмов закраски изображения нужно, чтобы полигоны были плоскими, т.е. их вершины должны лежать в одной плоскости - а треугольники таковы всегда по определению.) Т.е. формируем "геометрию" объекта. Затем накладываем по специальным алгоритмам цвет на наши полигоны. Как правило, делаем мы это с использованием заранее нарисованных плоских изображений - текстур (этот процесс называется закраской).
С созданием "геометрии" объекта (и сцены в целом) может справиться центральный процессор (что и происходит), но когда дело доходит до закраски, средствами одного центрального процессора (CPU) нам не обойтись. Ведь "натягивание" текстур на полигоны - довольно трудоемкая задача (для жалких сотни треугольников приходится рассчитывать как минимум 7–8 миллионов точек в секунду, если мы хотим получить приемлемое число кадров в разрешении 1024ґ768). Если заставить CPU помимо расчета геометрии еще и текстурами заниматься, пожалуй, многовато для него будет. Но самое главное - текстуры зачастую являются очень большими изображениями и, в отличие от небольшого набора геометрической информации, в кэш-память процессора не помещаются, тем самым вынуждая его непрерывно обращаться к далеко не такой быстрой как кэш оперативной памяти. Таким образом, закраска становится бутылочным горлышком при отрисовке сцены, и именно для аппаратного ускорения соответствующих операций были созданы первые 3D-акселераторы.
Но даже когда мы создали объект и закрасили его, нужно озаботиться еще и освещением. Тут особая свистопляска, в которую мы пока соваться не будем - да поможет вам Гуро с его методом (Gouraud method - лег в основу ускорителей с фиксированным конвейером (Fixed Function Pipeline (FFP)): видеокарты поколения DirectX 7), позволяющим эффективно и быстро добиться хорошего результата. Конечно же, первые ускорители рассчитывать освещение не могли. Но это не говорит о том, что игры были убогие - нет, разработчики выкручивались как могли, создавая вполне реалистичные проекты. Даже с тенями. Движок игры сам заблаговременно рассчитывал освещенность объектов и создавал соответствующие текстуры освещения, т.е. ускоритель рисовал уже просчитанные блики света. Для статического освещения подход хороший, но динамика выглядела ужасно - не сравнить с современными играми, рассчитывающими освещение "на лету". Как следствие, из-за возросшей нагрузки на центральный процессор, 3D-ускорители впоследствии получили аппаратный блок геометрических вычислений - Hardware Transform & Lightning (T&L - трансформация и освещение). После этого освещенные объекты все же оставались плоскими, гладкими и не сильно-то реалистичные, но и против этой напасти быстро нашли решение. Модифицировав алгоритм расчета цвета точки, мы можем, не усложняя геометрическую модель, радикально улучшить ее внешний вид. Такая техника получила название bump mapping (впервые появилось у Matrox (Environment Bump Mapping), а затем и у NVIDIA (DOT3). Конечно, bump mapping - не панацея от всех бед, для улучшения картинки применяется еще куча специальных техник и методов, например метод Фонга или его улучшенные варианты). Но ее реализация (и не только ее) требовала возможности программирования пиксельных конвейеров, т.е. шейдеров.
Шейдер - небольшая программа, позволяющая программировать графический ускоритель. На практике шейдер - короткая последовательность машинных кодов, которую разработчик, как правило, описывает на специальной разновидности ассемблера (правда, NVIDIA уже давно предлагает C-компилятор шейдеров - Cg. а в DirectX 9.0c Microsoft включила стандартный High-Level Shader Language (HLSL) ). При этом шейдер позволяет творить настоящие чудеса с простыми моделями. Например, персонажи Doom 3 построены из небольшого числа полигонов, но при поддержке ускорителем шейдеров этого совершенно не ощущаешь. Существует несколько их версий (Shader Model), о которых мы еще успеем поговорить по ходу разбора типов шейдеров.
К счастью, шейдеры не являются основной темой статьи, так что пройдемся по ним поверхностно. И начнем мы с вершинных шейдеров (Vertex Shader), которые являются естественным развитием идей T&L. Так сложилось, что блок T&L ускоряет некоторые геометрические преобразования, и поэтому без особых махинаций мы можем поручить ему более широкий класс задач, "откусив" попутно у CPU часть функций, чтобы без его непосредственного участия шевелить траву и листья деревьев в сцене, детализировать на лету близкие объекты и огрублять дальние. Попутно разработчик получает полный контроль над механизмами T&L и может использовать вершинные шейдеры для расчета специфической геометрической информации, которую потом будут использовать пиксельные шейдеры.
Вершинный шейдер даже первой версии при относительно небольших объемах геометрических вычислений в процессе рендеринга может быть довольно сложной многострочной программой. Впрочем, первая версия вершинных шейдеров имела достаточно большие ограничения - не допускались никакие переходы (тем более не было условных переходов и, ясное дело, циклов), т.е. в ходу были прямолинейные и простые программы. Вторая версия шейдеров с некоторыми ограничениями допускает условные переходы и циклы. (В двух словах: условные переходы - это команда на изменение порядка выполнения программы в соответствии с результатом проверки некоторого условия. Очень распространенная, надо сказать, команда, и довольно проблематичная для вычислительного устройства (потеря времени). С циклами, думаю, все понятно.) А еще шейдера второго поколения позволяют организовывать функции, благодаря чему можно реализовать практически любой алгоритм. Третья версия стала еще более "демократичной" - она позволяет использовать в вычислениях текстуры и создавать "свои" свойства для вершин - таким образом, вершинный блок постепенно становится полноценным процессором с нешуточными возможностями.
Конечно, при этом стоит учитывать, что вершинные шейдеры, по сути, существуют для разгрузки центрального процессора, и их легко можно имитировать драйверами, "подсовывая" обычный CPU вместо соответствующего блока в видеокарте. А вот с пиксельными шейдерами такой номер не пройдет. Их просто нечем заменить. Отчасти поэтому я считаю их одним из главных и фундаментальных составляющих современного GPU. И говоря о шейдерах и их версиях, как правило, имеют в виду именно пиксельные шейдеры.
Пиксельный шейдер (Pixel Shader) обычно задает модель расчета освещения отдельно взятой точки изображения, производят выборку из текстур и/или математические операции над цветом и значением глубины. Пиксельные шейдеры могут автоматически генерировать текстуры (например, стилизация под дерево, или под воду, или блики на дне ручья, отбрасываемые рябью на его поверхности, причем текстуры, изменяющиеся во времени и не теряющие детализации даже при приближении к ним), а также производить с текстурами различные операции (например, мультитекстурирование - наложение нескольких слоев текстуры). Если говорить образно, пиксельный шейдер - это рельефные стены и естественное освещение (в том числе и динамическое и от многих источников света), рябь на воде, блики света на металлических и стеклянных поверхностях, очень реалистично выглядящие "пористые" поверхности и разнообразные спецэффекты. Т.е. это все то, чем мы восхищаемся в красивых и динамичных игрушках (тот же Doom 3 с его тенями и интерьерами, или вспомните воду в FarCry). Правда, пиксельный шейдер не столько вычисляет, сколько изменяет некий предварительно вычисленный стандартными способами цвет, поэтому даже если ваша видеокарта не поддерживает пиксельные шейдеры, то она все-таки сможет (не всегда, конечно) кое-что выдать на экран.
Но как вы понимаете, отработка пиксельных шейдеров - это колоссальная нагрузка на графический ускоритель (например, для хранения больших текстур нужно много памяти, а работа с ними может с легкостью озадачить даже самую производительную систему). Но овчинка стоит выделки! Реалистичность игрового мира - это вам не шутки, ради нее можно и побороться. Но благо нагрузка велика, ограничения на шейдерную программу здесь гораздо жестче, чем в случае вершинных шейдеров. Помимо арифметических манипуляций присутствуют и специализированные "текстурные", осуществляющие выборки цвета и арифметические вычисления с данными текстур. Что касается различий между версиями пиксельных шейдеров, они, аналогично вершинным шейдерам, отображают тот же эволюционный принцип: от полного ограничения к постепенному увеличению возможностей. Так, пиксельный шейдер первой версии поддерживал не больше восьми арифметических инструкций и не более четырех текстурных. Шейдеры версии 1.4 - те же восемь арифметических, но уже шесть текстурных инструкций, и без каких либо условных переходов. А вот во второй версии случилась маленькая революция - появилась поддержка чисел с плавающей точкой. Это позволило превысить стандартный диапазон 8-битного цвета, которого явно не хватало для отображения всего богатства оттенков. Третья версия шейдеров не принесла ничего особенного - включена поддержка условных переходов. Для освещения эта функция практически бесполезна. Но для "математических" операций как нельзя кстати, так как позволяла добиться некоторой оптимизации производительности шейдеров (например, можно не проводить вычислений над заведомо бесперспективными пикселами).
Это все хорошо, но до сих пор непонятно, как это все работает в результате. Постараемся в этом разобраться.
Есть такая интересная штука - графический конвейер, который реализует обработку графики конвейерным способом. И работает он следующим образом:
На первом этапе в графический процессор поступают данные от CPU об объекте, который надо построить. Эта информация попадает в блок вершинных процессоров и обрабатывается в нем (не путайте "блок вершинных процессоров" и "вершинные процессоры": блок - это совокупность вершинных процессоров, работающих по принципу конвейера. То же самое относится и к пиксельным процессорам). Вершинный конвейер (Vertex Pipeline) занимается расчетом геометрии сцены и определяет положение вершин, которые при соединении образуют каркасную модель трехмерного объекта, плюс осуществляет математические операции с вершинами (изменение параметров вершин и их освещения, этим занимается блок T&L). Все это происходит под управлением вершинных шейдеров. Тут по сути ничего сложного нет, про вершинные шейдеры мы уже успели достаточно поговорить.
После блока вершинных конвейеров данные поступают в следующий блок (Triangle), где происходит сборка (Setup) трехмерной модели в полигоны. После чего они попадают в блок пиксельных процессоров (Pixel Pipeline). Где и происходит операция закраски, плюс средствами пиксельных шейдеров происходит растеризация (процесс разбиения объекта на отдельные точки - пикселы) для каждого пиксела изображения, а также еще некоторые интересные вещи, о которых мы уже говорили (мультитекстурирование, попиксельное освещение, создание процедурных текстур, постобработка кадра и т.д.). Затем данные попадают в блок растровых операций ROP (Raster Operations Pipes), где с использованием буфера глубины (Z-буфера) определяются и отбрасываются те пикселы, которые не будут видны пользователю (в данном кадре). Также реализуется обеспечение полупрозрачности. В данном блоке происходят не менее интересные вещи: Antialiasing (т.е. сглаживание - удаление "лесенки" на изогнутых линиях путем добавления вокруг пикселов, создающих прямые линии из других пикселов, немного других оттенков), Blending (если кратко - плавный постепенный переход от одного цвета к другому, или преобразование одной геометрической формы в другую). Потом в ROP снова собираются все фрагменты (пикселы) в полигоны, и уже обработанная картинка передается в кадровый буфер (frame buffer). Данный буфер нужен для того, чтобы вывод и формирование картинки не зависели друг от друга. И так как монитору нужно непрерывно получать видеосигнал из данного буфера, применяется специальный преобразователь RAMDAC (RAM Digital-to-Analog Convertor - цифро-аналоговоговый преобразователь памяти), который непрерывно читает кадровый буфер и формирует сигнал, передаваемый через дополнительные схемы на выход видеокарты. Аналогично могут формироваться цифровые или телевизионные выходные сигналы. Причем, у современных GPU, как правило, несколько RAMDAC, что позволяет одновременно и независимо выводить видеосигналы на несколько мониторов одновременно.
Вышеописанный "классический" графический конвейер дает нам наглядное представление об основных этапах формирования изображения видеокартой. Конечно, графический конвейер я описал в сильном упрощении, там куда более сложные дела творятся, но, на мой взгляд, и того достаточно. Но самое главное то, что в GPU не один, а несколько конвейеров, работающих параллельно, и чем их больше, тем более производительным является GPU. Но стоит также учитывать то, что "графический конвейер" - понятие условное, так как в графическом процессоре используются несколько разных конвейеров (т.е. пиксельные или вершинные процессоры), которые выполняют различные функции. В этом смысле более правильно говорить о вершинных или пиксельных конвейерах, но не о конвейерах вообще. Хотя сложилось так, что под конвейером понимали пиксельный процессор, который подключен к своему блоку наложения текстур (TMU (Texture Module Unit) - текстурные блоки, о них мы успеем поговорить отдельно). Например, если у GPU шестнадцать пиксельных процессоров, каждый из которых подключен к своему блоку TMU, то принято говорить, что у GPU шестнадцать конвейеров. Но отождествлять число графических конвейеров с числом пиксельных процессоров все-таки не совсем корректно, поскольку конвейерная обработка подразумевает работу не только с пикселами, но и с вершинами, а значит, необходимо учитывать и количество вершинных процессоров. Так что число конвейеров будет корректной характеристикой GPU, только если их количество совпадает с числом пиксельных и вершинных процессоров и блоков TMU. И дело в том, что равное число различных конвейеров было бы самым производительным решением, если бы нагрузка на каждый из процессоров (будь-то вершинные или пиксельные) была одинакова. Но в реальной ситуации все совсем не так идиллично - нагрузка, как правило, неравномерна, и поэтому приходится искать оптимальный подход, комбинируя процессоры в зависимости от потребностей. Так как важно не переборщить с геометрическими характеристиками и в то же время не пренебречь красотами мультитекстурирования и роскошью сложных пиксельных шейдеров. И из-за этого имеем разное число пиксельных и вершинных процессоров, причем каждый производитель определяет свою пропорцию. Но решение проблемы золотой середины между количественным соотношением процессоров уже существует, о нем мы еще вспомним.
Я надеюсь, вы уже заметили, что мы вплотную подошли к архитектуре GPU, и конечно, на достигнутом мы останавливаться не будем. Причем, "глазеть под капот" мы начнем, так сказать, с "доунифицированной" архитектуры. Это затем, чтобы потом было ясно, что нового дает нам эта унифицированная архитектура и что изменилось. Но не беспокойтесь, закапываться глубоко мы не будем, и тем более опускаться в "дошейдерную" эпоху (хотя по иронии судьбы данные строки пишутся на компьютере, в котором стоит GeForce 2 MX400), а начнем с более свежих графических ускорителей.
И первым у нас будет GPU от NVIDIA, так как на примере данного GPU можно легко разобраться в устройстве "классической" архитектуры, а заодно усвоить некоторые понятия и термины - просто чтобы не отвлекаться потом.
Итак, вышедший в 2005 г. графический чип G70 (GeForce 7800) стал дальнейшим эволюционным развитием чипов NV4x (ранее G70 значился как NV47, т.е. он относится к тому же поколению чипов, что и GeForce 6800). Имеет 24 пиксельных конвейера, по одному текстурному блоку на конвейер (т.е. 24 TMU), 8 вершинных конвейеров и 16 блоков растровых операций (ROP). Остальные характеристики можно посмотреть в сравнительной таблице. А теперь внимательно смотрим на схему и разбираемся.
G70 (GeForce 7800)