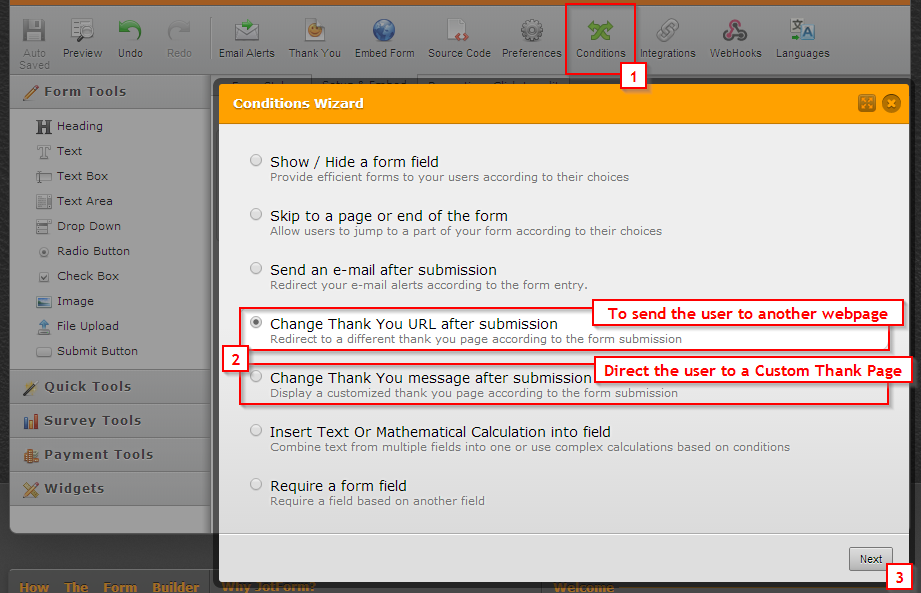


 Рейтинг: 4.7/5.0 (1914 проголосовавших)
Рейтинг: 4.7/5.0 (1914 проголосовавших)Категория: Windows: Менеджеры закладок
 Robots.txt — это файл ограничения доступа роботам поисковых систем к содержимому сайта, расположенного на http-сервере. Файл robots.txt должен находиться в корневой папке сайта (то есть иметь путь относительно имени сайта:
Robots.txt — это файл ограничения доступа роботам поисковых систем к содержимому сайта, расположенного на http-сервере. Файл robots.txt должен находиться в корневой папке сайта (то есть иметь путь относительно имени сайта:
/robots.txt ).
При наличии нескольких поддоменов, файл robots.txt должен располагаться в корневом каталоге каждого из них. Данный файл дополняет стандарт Sitemaps. который служит прямо противоположной цели: облегчать роботам доступ к содержимому.
Использование файла robots.txt добровольное, т.е. не является обязательным. Стандарт исключений для роботов (robots.txt ) был принят консорциумом W3C 30 января 1994 года в списке рассылки robots-request@nexor.co.uk и с тех пор используется большинством известных поисковых систем.
Файл robots.txt используется для частичного управления индексированием сайта поисковыми роботами. Этот файл состоит из набора инструкций для поисковых роботов, при помощи которых можно задать файлы, страницы или каталоги сайта, которые не должны индексироваться. Файл robots.txt может использоваться для указания расположения файла и может показать, что именно нужно, в первую очередь, проиндексировать поисковому роботу.
Это здорово, когда роботы поисковых систем часто посещают сайт и индексируют ваш контент, но часто бывает так, что индексация части вашего онлайн-контента нежелательна. Например, если у вас есть два варианта страницы (одна для просмотра в браузере, а вторая - для печати), то печатную версию желательно исключить из сканирования, иначе вы рискуете получить штраф за дублирование контента.
Кроме того, в случае, если вы храните конфиденциальные или важные данные, не предназначенные для посторонних глаз, то вы также предпочли бы, чтобы поисковые системы не индексировали такие страницы. Хотя, в данном случае, верный путь для сохранения от индексирования конфиденциальных данных - это держать их в локальном каталоге на своем компьютере или защитить доступ с помощью пароля.
Кроме того, если вы хотите скрыть некоторые свои профессиональные наработки, исключая их из индексации (к примеру, изображения, таблицы стилей или JavaScript), то необходимо иметь способ дать знать роботам, чтобы они держались подальше от этих элементов. Одним из таких способов является использование мета-тега Robots. Но поскольку не все поисковые системы могут читать мета-теги. то мета-тег Robots может просто остаться незамеченным. Лучший способ сообщить поисковым системам о вашей воле - использовать файл robots.txt .
Ниже вы найдете схематическое изображение того, как выглядят сайты с файлом robots.txt и без него.
Что такое robots.txt ?Robots.txt - это текстовой (не HTML) файл, который размещается на сайте, чтобы сообщить поисковым роботам, какие страницы они не должны посещать. Указания файла robots.txt отнюдь не обязательны для поисковых систем, но, в целом, поисковики подчиняются тому, что вебмастера просят не делать. Важно уточнить, что файл robots.txt не является способом предотвращения сканирования вашего сайта поисковой системой.
Тот факт, что вы поместили файл robots.txt. сродни тому, что повесить записку: «Пожалуйста, не вводите" на незапертую дверь, например, т.е. вы не можете предотвратить воров войти в нее, а нормальные люди, прочитав записку, не будут пытаться войти. Вот почему было сказано, что если у вас на сайте действительно размещена важная информация, то слишком наивно полагаться на то, что robots.txt защитит ее от индексации и отображения в результатах поиска.
Размещение файла robots.txtМесто расположения файла robots.txt на сайте - очень важно. Файл должен быть расположен в корневой директории сайта. потому что в противном случае поисковые системы не смогут его найти – они не будут искать по всему сайту файл с именем robots.txt. Вместо этого, они сначала смотрят в основной каталог (например, http://mysite.com/robots.txt ) и, если они не найдут его там, то просто предполагают, что этот сайт не имеет файла robots.txt и поэтому они индексируют все, что находят на своем пути.
Таким образом, если вы не разместите файл robots.txt со своими указаниями в нужном месте, не удивляйтесь, что поисковые системы проиндексируют весь сайт, включая и то, что вам не хотелось сделать достоянием гласности.
Создание robots.txtДля создания файла robots.txt можно использовать любой текстовый редактор (Блокнот, Notepad++ и т.д.). Если вы не планируете запрещать к индексации какие-то данные, то можно просто создать пустой файл с названием: «robots.txt » и разместить его в корневой директории сайта.















Web site owners use the /robots.txt file to give instructions about their site to web robots; this is called The Robots Exclusion Protocol.
It works likes this: a robot wants to vists a Web site URL, say http://www.example.com/welcome.html. Before it does so, it firsts checks for http://www.example.com/robots.txt, and finds:
The "User-agent: * " means this section applies to all robots. The "Disallow: / " tells the robot that it should not visit any pages on the site.
There are two important considerations when using /robots.txt:
So don't try to use /robots.txt to hide information.
The detailsThe /robots.txt is a de-facto standard, and is not owned by any standards body. There are two historical descriptions:
The /robots.txt standard is not actively developed. See What about further development of /robots.txt? for more discussion.
The rest of this page gives an overview of how to use /robots.txt on your server, with some simple recipes. To learn more see also the FAQ.
How to create a /robots.txt file Where to put itThe short answer: in the top-level directory of your web server.
The longer answer:
When a robot looks for the "/robots.txt" file for URL, it strips the path component from the URL (everything from the first single slash), and puts "/robots.txt" in its place.
For example, for "http://www.example.com/shop/index.html. it will remove the "/shop/index.html ", and replace it with "/robots.txt ", and will end up with "http://www.example.com/robots.txt".
So, as a web site owner you need to put it in the right place on your web server for that resulting URL to work. Usually that is the same place where you put your web site's main "index.html " welcome page. Where exactly that is, and how to put the file there, depends on your web server software.
Remember to use all lower case for the filename: "robots.txt ", not "Robots.TXT.
What to put in itThe "/robots.txt" file is a text file, with one or more records. Usually contains a single record looking like this:
In this example, three directories are excluded.
Note that you need a separate "Disallow" line for every URL prefix you want to exclude -- you cannot say "Disallow: /cgi-bin/ /tmp/" on a single line. Also, you may not have blank lines in a record, as they are used to delimit multiple records.
Note also that globbing and regular expression are not supported in either the User-agent or Disallow lines. The '*' in the User-agent field is a special value meaning "any robot". Specifically, you cannot have lines like "User-agent: *bot*", "Disallow: /tmp/*" or "Disallow: *.gif".
What you want to exclude depends on your server. Everything not explicitly disallowed is considered fair game to retrieve. Here follow some examples:
To exclude all robots from the entire server To allow all robots complete access(or just create an empty "/robots.txt" file, or don't use one at all)
Любой оптимизатор должен знать способ общения с поисковыми роботами. Robots.txt – это обыкновенный текстовый файл, в котором записаны инструкции для них. Его используют для запрета индексации некоторых страниц сайта, соблюдения заданных временных интервалов для скачивания роботом документов с сервера и т.п. Для того чтобы он понял данные инструкции, необходимо уметь их объяснять на особом языке. В данной статье я расскажу, как научиться общаться с поисковыми роботами.
Где находится Robots.txt?Для начала вам необходимо создать пустой файл robots.txt в блокноте. Сам файл всегда должен находится в корневой папке сайта. Если вы не хотите запрещать индексацию страниц или указывать другие команды, просто оставьте файл пустым. Дело в том, что первым делом поисковый робот, заходя на сайт, ищет там файл с именем «robots.txt» и, если находит там инструкции – следует им, а если не находит – просто начинает индексацию страниц.
Итак, размещать файл с инструкциями необходимо в корне сайта, поскольку затерявшийся в поддиректориях robots.txt не сможет быть прочтён поисковым роботом. То есть файл должен быть размещён по адресу http :// mysite.ru/robots. txt. Необходимо учитывать, что на сайте не должно быть более одного robots.txt.
Как настроить Robots.txt?Для того чтобы ответить на данный вопрос, сначала рассмотрим основные директивы, которые могут прописываться в файле. Затем расскажем об особенностях их использования для отдельных поисковых систем.
User-agent – это директива, указывающая, к каким роботам будут относиться те или иные команды. Так, например, если вы укажете в файле команду user-agent:*, то нижеследующая директива будет служить указанием для любых роботов, а если после двоеточия последует название робота, то это указание будет касаться только его.
В качестве такого указания чаще всего выступает директива disallow. В таком случае после двоеточия может быть прописано:
Итак, простейшие файлы Robots.txt могут выглядеть следующим образом:
1.user-agent:*
#индексируются все страницы сайта.
2. user-agent: googlebot
Disallow: /private/
# робот googlebot обходит стороной каталог private.
(после знака «#» в файле обычно указываются комментарии)
Allow – это директива, которая является противоположной директиве disallow. То есть, прописывая в файле
user-agent: *
allow: /private/
disallow: /,
вы запрещаете всем роботам индексировать весь сайт, кроме каталога private.
Как настроить Robots.txt для поисковых систем Яндекс и Гугл?Для директивы user-agent: можно указать, каким именно роботам Яндекса следует индексировать ваш сайт. У данной поисковой системы есть такие роботы, как Yandeximages, Yandexdirect, Yandexnews, Yandexmedia и другие. У Гугла Googlebot – это основной робот. Кроме того, есть также Googlebot-image, Googlebot-mobile и т.п.
Яндекс устанавливает правила для вставки пустых строк между директивами. Так, перед каждой строкой user-agent: должна быть пустая строка, в то время как между user-agent: и disallowallow или между disallow и allow её быть не должно.
Следует уделить внимание спецсимволам «*» и «$» в поисковых системах Яндекс и Гугл. Первый символ означает, что вместо него может встречаться любая последовательность символов. Так, если мы укажем *.jpg, то команды робота будут относиться ко всем файлам сайта с таким расширением. Следует учитывать, что по умолчанию в Яндексе и Гугле в конце каждой команды ставится *.
Так, если вы пропишите в файле disallow:/images, то робот не будет индексировать ни images.htm, ни images.jpg, ни images.gif. Но есть выход. Знак $ в конце команды отменяет знак *, который ставится по умолчанию. То есть, если вы поставите его после images, то индексироваться не будет только images, а все остальные файлы с расширениями будут находиться в поле зрения робота.
Ещё одна важная директива – это Sitemap. Если у вашего сайта есть карта сайта, то это улучшит его индексацию, если в файле Robots.txt прописать после sitemap: путь к файлу, в котором содержится эта карта.
Кроме того, существует директива host. Она служит для определения роботом зеркал сайта (если таковые имеются) и главного зеркала. Для этой цели в качества параметра директивы следует указывать только главное зеркало в формате www. myhost.ru. Параметры, в составе которых есть двоеточие, тире, знак подчёркивания и другие символы, игнорируются роботами.
Следует учитывать, что у роботов разных поисковых систем имеются разные директивы, которые могут не подходить другим поисковикам. Кроме того, директивы могут быть чувствительны к регистру.
Итак, давайте посмотрим что такое URL. зачем он нужен и из каких частей состоит. Как вы знаете, поисковые системы производят индексацию сайтов ни как единого целого, а как совокупность отдельных web страниц. Те страницы вашего сайта, которые будут проиндексированы поисковиком, будут участвовать в ранжировании по различным поисковым запросам (читайте подробнее о подборе ключевых слов в Яндексе (wordstat.yandex.ru) на основе статистики запросов Яндекса, Google.ru и Рамблера, а так же про ранжирование и релевантность).
Ну так вот, любой документ (web страница) в сети интернет имеет свой уникальный адрес, который очень часто называют аббревиатурой URL (урл), которая расшифровывается как Uniform Resource Locator (определитель местонахождения ресурса). URL, равно как и протокол HTTP, а так же как и язык гипертекстовой разметки Html с валидатором W3C, был разработан и создан одним и тем же человеком — Тимом Бернерсом-Ли (отцом основателем проекта Всемирная паутина WWW — World Wide Web).
По большому счету URL является частным случаем другого идентификатора под названием URI (Uniform Resource Identifier — унифицированный идентификатор ресурса), но нам с вами все эти тонкости скорее всего будут не нужны (излишни) при работе со своим сайтом и его платной или бесплатной раскруткой. Давайте попробуем в общих чертах разобраться с тем, что такое URL и из каких частей он состоит, а потом перейдем к относительным и абсолютным ссылкам.
URL адрес — это способ однозначно указать на что-то в интернете. URL используется не только для работы с сайтами по протоколу http, но нас, конечно же, будет интересовать именно применение идентификатора URL применительно к Web (протоколы http и https). Например, URL применительно к Web будет выглядеть примерно так (чуть ниже я приведу общую блок-схему построения URL, но пока хотелось бы начать с простого частого примера):
Аббревиатура URL расшифровывается как Uniform Resource Locator. В переводе это значит «единый указатель ресурсов». Детище Тима Бернеса-Ли, «отца» всемирной паутины, создан для упрощения структурирования данных в сети Интернет и приведения всех адресов к единому виду.
Принятое произношение: «у-эр-эл» или «ю-ар-эл». В разговорной речи допустимо произносить эту аббревиатуру как «УРЛ». В этой статье мы рассмотрим что такое URL, какова его структура и технические особенности которые необходимо знать любому веб-мастеру.
Схема и структура URL адресовЧто же такое URL? Иными словами, это путь до какого-то файла: HTML, видео, аудио, текстового и пр. Этим адресом обладают все документы, находящиеся в сети Интернет. Только с помощью URL сервер может обеспечить доступ к своим файлам для любого пользователя всемирной паутины.
Разумеется, существует стандарт. Он-то и определяет, как именно должен выглядеть URL к тому или иному документу. Этот стандарт используется не только для доступа к сайтам и файлам, по протоколу http и https, его же используют и при передаче файлов на сервер по протоколу ftp и в других протоколах. Но нас они в данном случае не интересуют.
Как указать url адрес к веб-ресурсам?Вообще URL может содержать множество параметров. Но для простого обращения к определенному файлу лежащему в какой то папке вашего сайта необходимо задействовать лишь некоторые из них. Поэтому, например, чтобы получить содержимое определенного файла размещенного на данном сайте достаточно указать следующее:
Давайте рассмотрим все подробно:
Как видно, папки и файлы разграничиваются знаком "/", который называется "слеш". Путь может быть длиннее. Кроме этого доменное имя может быть указанно с WWW и без WWW. Т. е. может быть: http://www.webmastermix.ru. Это не обязательный параметр, поэтому без разницы укажете вы его или нет необходимый вам файл все равно откроется. Для упрощения его лучше не использовать. И если ваш сайт доступен по двум адресам т. е. с WWW и без WWW, то лучше склеить эти URL и привести к одному виду, где WWW не будет использоваться. Как это сделать читайте в статье: Как настроить 301 редирект в htaccess и в скриптах - более 18 примеров использования .
В общем и целом, что такое url сайта, страницы или изображения ясно. А теперь немножко углубимся.
Структура URL-адресаОбщая схема (структура) URL-адреса следующая:
Каждый из этих параметров важен и имеет своё значение:
1. В URL адресах используются различные кодировки. Если перекодирования нет, использовать можно только определённое количество символов. Рекомендуется использовать символы [0-9],[a-z],[A-Z],[_],[-].
Чтобы избежать ошибок, разработчик должен именовать файлы сайта только в нижнем регистре и путь к ним указывать точно так же – маленькими буквами. Потому как, на юникс-подобных системах, а на них, чаще всего, работают веб-серверы, символы, написанные в разных регистрах, будут восприниматься машиной как разные. В Windows такого нет, но пренебрегать правилом, всё же, не стоит потому как если ваш файл назван в нижнем регистре, а в URL его название вы указали в верхнем регистре, то сервер не сможет его открыть.
Русские символы использовать можно, однако каждый русский символ будет проходить перекодировку (URL Encoding). И этой после перекодировки они будут выглядеть «страшно», ведь любой символ кириллицы будет закодирован с помощью 2 байт в UTF-8 в шестнадцатеричном виде. Разделяются символы знаком «%».
Правильный файл robots.txt для Drupal с точки зрения SEO в первую очередь предназначен для борьбы с дублями страниц сайта. Кроме того "правильный" подразумевает в том числе и то, что на сайте установлены и другие "правильные вещи": во-первых, стоит модуль pathauto (который в частности подразумевает включенные "чистые ссылки"), а во-вторых, стоит модуль Global Redirect. предназначенный для автоматической переадресации с "внутридрупаловских" URL (типа node/123 ) на их синонимы (т.е. URL. сделанные пасавто ).
Важно подчеркнуть ещё раз, что если ваш сайт на Друпале. но у него какие-то специфические требования либо не стоят вышеупомянутые модули для автоматического создания синонимов и последующей принудительной переадресации (редиректа) на них, то использование подобного "правильного" robots.txt может привести к не желательным результатам. Это значит, что все такие вещи нужно применять с пониманием сути.
С другой стороны, если вы действительно хотите получить максимум "сео-эффекта" и сделали всё верно - не пытайтесь "улучшать" подобные "правильные" роботы, опять же, чётко не понимая смысла своих действий, т.к. даже перестановка (изменение последовательности) директив может привести к вылету из индекса сайта или его части.
Use our Robots.txt generator to create a robots.txt file.
Analyze Your Robots.txt FileUse our Robots.txt analyzer to analyze your robots.txt file today.
Example Robots.txt FormatUser-agent: *
Disallow: /
Disallow: /folder/
Disallow Googlebot from indexing of a folder, except for allowing the indexing of one file in that folder
User-agent: Googlebot
Disallow: /folder1/
Allow: /folder1/myfile.html
Background Information on Robots.txt Files
User-agent: Slurp
where the 5 is in seconds.User-agent: bingbot
Crawl-delay: 10
where the 10 is in seconds.
User-agent: *
Disallow: /*?
You can use the $ character to specify matching the end of the URL. For instance, to block an URLs that end with .asp, you could use the following entry:
User-agent: Googlebot
Disallow: /*.asp$
More background on wildcards available from Google and Yahoo! Search.
URL Specific TipsPart of creating a clean and effective robots.txt file is ensuring that your site structure and filenames are created based on sound strategy. What are some of my favorite tips?
Google has begun entering search phrases into search forms, which may waste PageRank & has caused some duplicate content issues. If you do not have a lot of domain authority you may want to consider blocking Google from indexing your search page URL. If you are unsure of the URL of your search page, you can conduct a search on your site and see what URL appears. For instance,
User-agent: *
Disallow: /?s=
to your robots.txt file would prevent Google from generating such pagesTypically a noindex directive would be included in a meta robots tag. However, Google for many years have supported using noindex inside Robots.txt. similarly to how a webmaster would use disallow.
User-agent: Googlebot
Disallow: /page-uno/
Noindex: /page-uno/
The catch, as noticed by Sugarrae. is URLs which are already indexed but are then set to noindex in robots.txt will throw errors in Google's Search Console (formerly known as Google Webmaster Tools). Google's John Meuller also recommended against using noindex in robots.txt.
Secured Version of Your Site Getting Indexed?In this guest post by Tony Spencer about 301 redirects and .htaccess he offers tips on how to prevent your SSL https version of your site from getting indexed. In the years since this was originally published, Google has indicated a preference for ranking the HTTPS version of a site over the HTTP version of a site. There are ways to shoot yourself in the foot if it is not redirected or canonicalized properly.
Have Canonicalization or Hijacking Issues?Throughout the years some people have tried to hijack other sites using nefarious techniques with web proxies. Google. Yahoo! Search. Microsoft Live Search. and Ask all allow site owners to authenticate their bots.
Want to Allow Indexing of Certain Files in Folder that are Blocked Using Pattern Matching?Aren't we a tricky one!
Originally robots.txt only supported a disallow directive, but some search engines also support an allow directive. The allow directive is poorly documented and may be handled differently by different search engines. Semetrical shared information about how Google handles the allow directive. Their research showed:
The number of characters you use in the directive path is critical in the evaluation of an Allow against a Disallow. The rule to rule them all is as follows:
A matching Allow directive beats a matching Disallow only if it contains more or equal number of characters in the path
Comparing Robots.txt to. link rel=nofollow & Meta Robots Noindex/Nofollow TagsDisallow: Yandex
Правильно писать вот так:
User-agent: Yandex
Disallow: /
Указание нескольких каталогов в одной инструкции DisallowМногие владельцы сайтов пытаются поместить все запрещаемые к индексации каталоги в одну инструкцию Disallow.
Disallow: /css/ /cgi-bin/ /images/
Такая запись нарушает стандарт, и невозможно угадать, как ее обработают разные роботы. Некоторые могут «отбросить» пробелы и интерпретируют эту запись как «Disallow: /css/cgi-bin/images/». Некоторые могут использовать только первую или последнюю папки (/css/ или /images/ соответственно). Кто-то может просто отбросить непонятную инструкцию полностью.
Конечно, какие-то роботы могут обработать эту конструкцию именно так, как расчитывал веб-мастер, но расчитывать на это все же не стоит. Правильно надо писать так:
Disallow: /css/
Disallow: /cgi-bin/
Disallow: /images/
Имя файла содержит заглавные буквы