









 Рейтинг: 4.3/5.0 (1858 проголосовавших)
Рейтинг: 4.3/5.0 (1858 проголосовавших)Категория: Windows: Учет и контроль трафика
2014: 2.075
SNIP measures contextual citation impact by weighting citations based on the total number of citations in a subject field.SCImago Journal Rank (SJR):
2014: 1.287
SJR is a prestige metric based on the idea that not all citations are the same. SJR uses a similar algorithm as the Google page rank; it provides a quantitative and a qualitative measure of the journal’s impact.2014: 1.256
The Impact Factor measures the average number of citations received in a particular year by papers published in the journal during the two preceding years.
© Thomson Reuters Journal Citation Reports 20152014: 1.714
To calculate the five year Impact Factor, citations are counted in 2014 to the previous five years and divided by the source items published in the previous five years.
© Journal Citation Reports 2015, Published by Thomson Reuters
















A social network is a social structure made up of individuals (or organizations) called "nodes", which are tied (connected) by one or more specific types of interdependency, such as friendship. kinship. common interest, financial exchange, dislike, sexual relationships. or relationships of beliefs, knowledge or prestige .
Social network analysis (SNA) views social relationships in terms of network theory consisting of nodes and ties (also called edges. links. or connections ). Nodes are the individual actors within the networks, and ties are the relationships between the actors. The resulting graph -based structures are often very complex. There can be many kinds of ties between the nodes. Research in a number of academic fields has shown that social networks operate on many levels, from families up to the level of nations, and play a critical role in determining the way problems are solved, organizations are run, and the degree to which individuals succeed in achieving their goals.
In its simplest form, a social network is a map of specified ties, such as friendship, between the nodes being studied. The nodes to which an individual is thus connected are the social contacts of that individual. The network can also be used to measure social capital – the value that an individual gets from the social network. These concepts are often displayed in a social network diagram. where nodes are the points and ties are the lines.
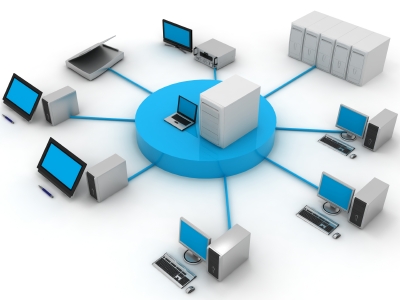
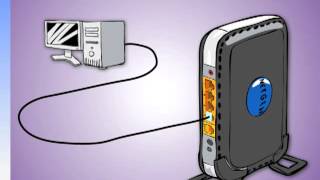
(n.) A network is a group of two or more computer systems linked together. There are many types of computer networks. including the following:
In addition to these types, the following characteristics are also used to categorize different types of networks:
Computers on a network are sometimes called nodes . Computers and devices that allocate resources for a network are called servers .
(v.) To connect two or more computers together with the ability to communicate with each other.
Top 5 Network Related QuestionsBy Bradley Mitchell. Wireless/Networking Expert
Bradley is a computer professional with 20 years experience in network software development, project management, and technical writing. He has covered wireless and computer networking topics for About.com since 1999. See also - Bradley Mitchell at Google+
Continue Reading Below
LAN and WAN are the two primary and best-known categories of area networks, while the others have emerged with technology advances
Note that network types differ from network topologies (such as bus, ring and star). (See also - Introduction to Network Topologies .)
LAN - Local Area NetworkA LAN connects network devices over a relatively short distance. A networked office building, school, or home usually contains a single LAN, though sometimes one building will contain a few small LANs (perhaps one per room), and occasionally a LAN will span a group of nearby buildings.
In TCP/IP networking, a LAN is often but not always implemented as a single IP subnet .
In addition to operating in a limited space, LANs are also typically owned, controlled, and managed by a single person or organization. They also tend to use certain connectivity technologies, primarily Ethernet and Token Ring .
WAN - Wide Area NetworkAs the term implies, a WAN spans a large physical distance. The Internet is the largest WAN, spanning the Earth.
A WAN is a geographically-dispersed collection of LANs.
Continue Reading Below
A network device called a router connects LANs to a WAN. In IP networking, the router maintains both a LAN address and a WAN address.
A WAN differs from a LAN in several important ways. Most WANs (like the Internet) are not owned by any one organization but rather exist under collective or distributed ownership and management. WANs tend to use technology like ATM. Frame Relay and X.25 for connectivity over the longer distances.
LAN, WAN and Home NetworkingResidences typically employ one LAN and connect to the Internet WAN via an Internet Service Provider (ISP) using a broadband modem. The ISP provides a WAN IP address to the modem, and all of the computers on the home network use LAN (so-called private ) IP addresses. All computers on the home LAN can communicate directly with each other but must go through a central network gateway. typically a broadband router. to reach the ISP.
Other Types of Area NetworksWhile LAN and WAN are by far the most popular network types mentioned, you may also commonly see references to these others:
What Is the Difference Between S-VLAN & Newlink?
Stacked Virtual Local Area Networks, or S-VLANs, and Newlink are different elements within the larger computer networking picture. S-VLAN is a method of organizing computers and devices across different networks… Read More
Tools to Analyze Peer-to-Peer Networking
You can analyze the overall performance, well-being and current status of a peer-to-peer network with some built-in Windows tools and third-party software. Peer-to-peer networks are so common that you may… Read More
How to Use VSLM for WAN & LAN Addressing Schemes
Variable Length Subnet Mask is a technique used to break apart packet routing on a computer network into subnets. While similar in basic function to the basic protocol used for… Read More
How to Turn on NAT on a Linksys
Opening NAT capabilities on your Linksys router so you can connect with a gaming system allows you to play many games over the internet. Though different gaming systems have different… Read More
How Do We Check Whether the Particular Port Is Open or Not?
With computer network ports ranging from 1 up to 65,535, malicious software can find thousands of ways to access a computer that's unprotected by a firewall. Trusted software, on the… Read More
Compatibility Between Gigabit & Fast Ethernet
Compatibility issues between Gigabit and Fast Ethernet segments of a network can cause data loss and transmission errors. A Gigabit interface communicating at full speed transmits data at too great… Read More
What Is a Packet Sniffing Recorder?
A packet sniffing recorder, also known as a network analyzer, is a computer program or piece of hardware designed to record and analyze traffic on a computer network. Network analyzers… Read More
Linksys Will Not Allow IP Renewal
Your Linksys router assigns IP addresses to your devices as you disconnect and reconnect your computer, smartphone or tablets to your home network. In the rare event that your device… Read More
What Is the Difference Between a Preferred DNS Server & an Alternate DNS Server?
Domain name system servers act as a kind of network directory service, translating URLs into IP addresses for computers and other devices to use. Without a connection to a working… Read More
How to Connect an Ethernet Switch to a Powerline Adapter
Powerline network adapters enable you extend your home network using your home electrical lines to carry network communication signals. Maximum network speed using powerline networking is about 500Mb per second,… Read More
Fastest Way to Fileshare From One Computer to Another
Windows has been using homegroups since Windows 7, with variations on the concept present in earlier versions as well. The idea is that a locally connected network of computers should… Read More
How to Monitor Home Linksys Networks for Free
Like most, you may have more than one device connected to the internet: your laptop, smart phones and your kids’ computers and phones. Monitoring the network then becomes necessary if… Read More
How to Find a D-Link Connection
If you have a D-Link router connected to your network, you can connect to the D-Link router in one of two ways. You can establish a direct connection between your… Read More
Congestion in a LAN
Congestion in a LAN, or local area network, can have several causes. If the LAN has been meeting performance requirements until now, start your investigation by determining what has changed… Read More
How to Reset a Password to an AirPort Extreme
Whether you've recently had unauthorized access attempts or simply feel it's time for a security refresh, it pays to know how to reset the password on your AirPort Extreme router.… Read More
What Are the Pros & Cons of Using a Bus Topology for a LAN?
The bus topology is a simple way of connecting computers together on a Local Area Network. One of the oldest networking topologies, a bus network has all of its devices… Read More
The Difference in TDM and TDMA
Time Division Multiplexing, or TDM, and Time Division Multiple Access, or TDMA, are forms of networking multiplexing -- a technology used for the analog or digital transmission of data packets.… Read More
I Cannot Run EXE Files on the Terminal Server
The use of the terminal server in the Windows operating system facilitates remote workstation capability, allowing many different computers to access the same system files from a central server. Security… Read More
The Ideal Bit Rate for Streaming HD Video on a Home Network
High-definition video provides a clearer and more defined picture than the consumer digital video often found on standard DVDs. When streaming HD video, you need to stream it at a… Read More
Trouble With HomeGroup & Norton 360
The Norton 360 security suite of programs is designed to protect your computer from a vast number of threats. This very protection can actually get in the way when you… Read More
How to Set Up DHCP for Multiple VLANs on Linux
A virtual local area network, OR VLAN, provides the ability to create multiple LANs within a single physical network. To set up DHCP for the VLANs, first set up the… Read More
The Differences Between HOSTS & LMHOSTS
In the Microsoft Windows operating system networking environment, a HOSTS file enables a computer to connect to the Internet. LMHOSTS files are plain-text files that instruct the computer on how… Read More
SCP vs. FTP Speed
Secure Copy Protocol and File Transfer Protocol both offer simple command line methods for transferring files between computers, but that's pretty much where the similarities end. SCP is better designed… Read More
What Is a Microsoft ISATAP Adapter?
Whenever new technology standards are introduced, there is often a transition period as companies and users begin adopting the new standard and leaving behind the old one. In the case… Read More
The USB 2.0 Ports Are not Working on my Alienware Laptop
Dell’s line of Alienware laptop computers comes with USB 2.0 ports that accommodate connections to devices which are compatible with USB 2.0 technology, such as mice and personal audio players.… Read More
Can You Stream Video Over USB?
Video files are frequently viewed on a computing device, such as a laptop or desktop computer, after the file has been transferred from another USB-equipped device, such as a digital… Read More
Why Is Acces Denied to My USB?
USB ports and devices make connecting to another computing device convenient. USB technology has been around since 1996, and is a feature found on most modern computing devices. If your… Read More
What Is a DNS Loopback?
A “loopback” is a networking concept that refers to an address that exists solely to redirect traffic back to the current computer. DNS is also concerned with addressing. It is… Read More
Unidentified Network on Windows 7
When a network comes up as “Unidentified” in Windows 7, it means that the operating system cannot find a way to access other network segments or the Internet. This often… Read More
What Is a Perimeter Router?
In simple terms, a perimeter router is a router -- a device that forwards units of data, known as packets, between networks -- that is installed on a perimeter segment… Read More
Can You Have Multiple PXE Servers on the Same Network?
The Pre-boot Execution Environment enables computers on a network to request an address and a start-up file automatically over a network when they power up. The scenario is initiated by… Read More
How Many Repeaters Can Be Used in a Network?
Network designers don’t count the total number of repeaters used on a network because they count the total number of repeaters used between two points or "nodes" on the network.… Read More
What Are the Benefits of Hierarchical Network Design?
Hierarchical network design provides efficient, fast and logical traffic forwarding patterns for enterprise network topologies while minimizing the cost of connecting multiple devices at network endpoints. First submitted as a… Read More
How to Run EXE From SharePoint
Microsoft's SharePoint software allows you to create intranet applications and websites for your company. To launch an application from the site, you link to the document that requires the EXE… Read More
VMware Cannot Ping
The most complex configuration of a virtual machine in VMware is the network setup, beginning with the decision to use bridged, host-only, NAT or custom. After you've configured the network… Read More
What Is Port 445 Used for in Windows 7?
Microsoft's Windows operating system has improved a lot over the years since Windows 3.1 was introduced. Windows 95, NT and other versions have led to Windows 7, which is more… Read More
How to Find the D-Link Security Code Using the Serial Number
Each D-Link router includes a default security code you use to connect to the router's console. D-Link offers customers a tool that returns a model number from a serial number.… Read More
How to Reduce Powerline Network Noise
Powerline networks use the electrical wires in a building to carry signals for a local area network, instead of using separate network cables. At the time of publication powerline networks… Read More
The Advantages of Bridging Network Connections
There are several ways to hook up individual computers into a network. One is to use hardware routers to link up the network segments. If you buy hardware bridges, those… Read More
How to Setup a Router With U-verse
At&T's U-Verse RG (Residential Gateway), also referred to as wireless gateways, function as both modems and wireless routers. But if your U-Verse RG uses an outdated wireless broadcast standard and… Read More
Nine Advantages of Database Processing
In the business world, the way your local computer network is set up can have an impact on the performance of your company. With database processing, a software application is… Read More
How to Block Computers From the Internet With a Netgear WNDR3300
You can block Internet access from any computers connected to your Netgear WNDR3300.The router includes a software interface designed for this type of administrative task. The software on the router… Read More
How to Delete Windows Disk Volume Powershell Script
The Windows Powershell utility is a shell prompt that lets administrators run advanced commands on the computer to manage user resources. The shell looks like a DOS command prompt, but… Read More
How to Disable STP on a One Port ProCurve
The Spanning Tree Protocol (STP) is a network protocol that is used with networks where multiple bridges, routers, hubs or switches are connected together. It is used to prevent looping… Read More
How to Hard Wire My PS3 When the Router Is in Another Room
The PlayStation 3 game console is the most advanced gaming console by Sony, as of the time of publication. It features an internal hard drive for game saves and other… Read More
What are RAS and IAS Servers?
A remote access server guards the entrance to a private network where it connects to either a phone line or the Internet. The RAS refers to an authentication server that… Read More
How to Monitor Visited Websites Using Wireshark
Wireshark can monitor all network traffic to and from your computer, and can also monitor network traffic from other computers on your network using "promiscuous" mode. Depending on your network… Read More
What Is a DNS Forwarder?
A DNS Forwarder is a type of proxy server. A proxy server acts on behalf of other computers. The World Wide Web uses an addressing system based on “domain names.”… Read More
How to Set Up a Spanning Tree on an HP ProCurve to Run a Redundant System
Enable the Spanning Tree Protocol -- known as STP -- on an HP Procurve switch infrastructure when configuring multiple network paths to each destination for fault tolerance. STP prevents network… Read More
Routed Vs. Switched Networks
Local network hardware is comprised of routers, switches, firewalls, gateways and cabling. Network hardware typically corresponds to the various "levels" of the OSI or DOD networking model -- such as… Read More
How to Enable DHCP on Enterasys
Configure the DHCP service on an Enterasys network switch appliance when the network requires basic DHCP services and a dedicated DHCP server is not available. Enterasys enterprise network switch appliances… Read More
How to Stretch a VLAN
A virtual local area network, or VLAN, is a network of computers or servers that share common requirements and the same broadcast domain, even if they aren't sharing the same… Read More
What Is LAN Based?
“LAN based” refers to applications or services that are accessible over a network. Although there are many products that can be accessed over a network, there are some that can… Read More
What Is CIFS in Mac OS X?
CIFS stands for Common Internet File System, and it's the standard for file and drive sharing in Microsoft Windows. Mac OS X has built-in capacity for connecting to a Microsoft… Read More
How to Heavily Stress Your Network
This may be the only article you’ll ever read containing the professional advice: Only try this trick at home. Stressing your home network is a good method for diagnosing weak… Read More
How to Reconnect to a Domain Controller Without Rebooting
When you connect to a Windows domain for the first time, you must reboot the Windows desktop. However, when you re-connect to the domain controller, you do not need to… Read More
How to Use the PsTools in PsExec
Using the PsExec tool on computers allows you to remotely execute programs on client computers connected to the same local network. PsExec is a command prompt application which is part… Read More
How to Mount an SMB on a PS3
SMB, or Server Message Block, is a logical construct in computer networking that allows network-enabled devices such as your computer and PS3 to connect and share files on a LAN,… Read More
What Is a LAN (100) Cable?
"Local Area Network" or LAN is a term meaning "private network." The dominant set of standards for the physical properties of LANs is called Ethernet. The Ethernet standards are published… Read More
How to Change the Duplex Setting on the Cisco 3550
Change duplex settings on a Cisco 3550 switch when you're connecting devices to the switch that do not support the current duplex settings, or when the duplex auto negotiation process… Read More
How to Check What VLAN You're On
Checking what Virtual Local Area Network you're on may not be possible, depending on the network hardware you're using and its drivers. Packets are tagged with the VLAN they belong… Read More
How to Drop Cables From the Attic Into a Wall
The same method of dropping a cable from the attic into a wall can be used for most types of cables. Because cables are usually coiled and will retain that… Read More
The Types of Ping Commands
The "ping" command is one of many tools in a network technician's toolbox, and it is one of the most useful. Ping is typically used to verify that a link… Read More
What Is UPnP?
You may have seen Universal Plug and Play (UPnP) listed as a feature on some of your home networking equipment or other devices -- such as your printer, home media… Read More
How to Export a GPO to a New Domain
The group policy object (GPO) contains all of your network's information including Windows users, security and desktop settings. You can export the GPO data from one domain to another to… Read More
How to Convert From RJ45 to RJ11
Although RJ-45 and RJ-11 connectors are generally not compatible, there may be occasions when you can convert a cable with RJ-45 connectors to an RJ-11 jack. RJ-45 connectors are usually… Read More
Client-Based Vs. Client-Server Networks
Client-server networks support a multitude of large businesses around the world, providing stability, security and centralized backup services. Client-based, or peer-to-peer, networks also provide networking services to many small companies,… Read More
How to Set Up NIC Teaming
NIC teaming is the process of linking or teaming network cards in a group or team to provide bandwidth aggregation or fault tolerance. NIC teaming can improved bandwidth performance considerably… Read More
How to Bridge a WRT150N Linksys Router With a DD-WRT SP2 Firmware to a GT704-WG-B Verizon Router
DD-WRT SP2 is freeware router firmware that is used to extend the features of many different routers, including the WRT150N Linksys router. One of its features is the increased capability… Read More
How to Fix iTunes Bonjour
Bonjour is a free utility created by Apple and distributed with software such as iTunes. Bonjour searches a local area network for services such as shared files and printers and… Read More
Can You Plug a Wireless Router Into a Phone Jack?
A wireless router is a device that transmits data to and from your Internet connection without requiring your computer to be connected to it by a cable. The router needs… Read More
How to Split a Subnet Into Two Subnets
Subnets are valuable tools for network administrators who want more control over individual notes on a network. While subnetting can never increase the number of addresses available, it does allow… Read More
What Is a DHCP Client ID?
The DHCP Client ID enables a computer to participate in Dynamic Host Configuration Protocol procedures. DHCP is a network administration tool that allocates an IP address to a computer over… Read More
How Can I Disable My Loopback Address?
The loopback address is an assigned IP (Internet Protocol) number of 127.0.0.1, which is designated and reserved for the software portion of a network interface. The loopback address is not… Read More
The Advantages & Disadvantages of a Switched Network
Switched networks have virtually replaced hub-based networks due to their ability to provide all of the bandwidth available on the wire by eliminating collisions. This advantage of switched networks played… Read More
What Is Thicknet and Thinnet?
Thicknet, also known as Thick Ethernet or 10Base5, and Thinnet, also known as Thin Ethernet or 10Base2, are obsolete Ethernet networking technologies. Both technologies use coaxial cable, which consists of… Read More
What Is an SNMP Port?
SNMP stands for Simple Network Management Protocol. SNMP is a network monitoring system, specifically designed to gather the status of devices attached to the network. A "port" in this context… Read More
How to Flash Dreambox Via a Network
If you have a Dreambox, a digital set-top box for your television - then you can flash the firmware to upgrade it. Dreambox devices are based on the Linux operating… Read More
How Do I Print out of VirtualBox?
VirtualBox is an open-source hypervisor software package originally created by Sun Microsystems and now maintained by Oracle. VirtualBox provides the functionality for an operating system such as GNU/Linux, Apple Mac… Read More
What Is an RJ45 Port?
The RJ45 port is the network port on a computer. This socket has many names. It is also known as the Ethernet port, the network adapter, the network jack or… Read More
How to Delete a VLAN Interface in Juniper
Juniper Networks manufactures a variety of data network products, including switches, routers and security appliances. Using the open standard from the Institute for Electronics and Electrical Engineers (IEEE), Juniper devices… Read More
What Is a Listening Port?
A port is an address for a program when data travels from one computer to another over a network. Just as computers have addresses, so do programs. The port number… Read More
How to Configure Access in VLAN Dynamic Mode
Dynamic Virtual Local Area Network (VLAN) mode allows a switch to automatically configure a port for a specific VLAN, based on the MAC address of the device connecting to the… Read More
How to Calculate Operational Availability
Operational availability is a ratio you can use when you have a computer network or system running. The operational availability is a way to measure how frequent your computer systems… Read More
What Are UPnP Settings?
As the Internet expands, it is used throughout the home in many home devices. Cell phones, televisions and even kitchen appliances are connecting to the Internet. The need to easily… Read More
CAT5e Vs. RJ45
CAT5e and RJ45 are two classifications of hardware for networks. Both are well-known components of Ethernet networks. The CAT5e classification of Unshielded Twisted Pair cable is the most widely implemented… Read More
The Advantages of a 2-Tier Client Server
Client-server is the traditional method of communication between two computers over a network, or between two programs on the same computer. The client initiates contact to request a resource. The… Read More
What Is a DHCP Server?
The Dynamic Host Configuration Protocol, or DHCP, is a method enabling network administrators to configure network software on computers on the network without physically visiting them. The DHCP server is… Read More
List of LAN Protocols
When you set up a local area network, you must specify a protocol. A protocol is a set of rules that allow each computer to communicate. Several LAN protocols exists,… Read More
What Is a PXE Server?
The Preboot Execution Environment is abbreviated to PXE. It is a method of connecting a computer to a network before its operating system has started up or any other of… Read More
How to Setup a VLAN
Computer networking has changed drastically over the last few decades. While at one time a slow, dial-up modem was considered high-tech, now homes, universities, government agencies and businesses are linked… Read More
How Many MBPs Is a Fast Internet?
Fast Internet, more appropriately known as Fast Ethernet, refers to several Institute of Electrical and Electronics Engineers (IEEE) 802.3 standards for local area networking, which provide data transfer rates of… Read More
What is an RJ45 Gigabit LAN Port?
Sockets on computers and network devices are known as “ports.” A network port is also called a LAN port -- LAN stands for local area network -- which is an… Read More
How to Ping a Device
Pinging a computer or device is a simple process. Ping is a command line utility used to test the connection between two devices within a network. Each device is represented… Read More
What Is a Node in a Network?
Networking nodes are the specific machines and routers within a network that allow that network to function. Each server, router, individual or local computer and printer with an Internet protocol… Read More
LAN Vs. PAN
The term LAN has been in common usage in the IT industry for decades. It stands for Local Area Network and means a private network covering a limited contiguous area.… Read More
What Is a LAN Repeater?
A LAN is a local area network -- tech-speak for a private network. A repeater is a piece of networking hardware. There are actually two types of repeaters. One is… Read More
What Is the Difference Between a Hub & a Concentrator?
A "concentrator" in a computer networking domain is any physical device serving as a network node connecting multiple computers and peripheral devices. In terms of the popular Ethernet network, the… Read More
How to Set Up a Network Printer on the MacBook Pro
A network printer connects to your local network through a Wi-Fi or Ethernet connection. Set up a network printer on your MacBook Pro by configuring the printer to join your… Read More
Wireless Vs. Wired Speed
With advancements in routing technology, the differences in speed between wired and wireless networks have begun to blur. Traditional knowledge indicates that wired networks offer a connection superior to that… Read More
Hi there, I'm a CS PhD student at Stanford. I've worked on Deep Learning for a few years as part of my research and among several of my related pet projects is ConvNetJS - a Javascript library for training Neural Networks. Javascript allows one to nicely visualize what's going on and to play around with the various hyperparameter settings, but I still regularly hear from people who ask for a more thorough treatment of the topic. This article (which I plan to slowly expand out to lengths of a few book chapters) is my humble attempt. It's on web instead of PDF because all books should be, and eventually it will hopefully include animations/demos etc.
My personal experience with Neural Networks is that everything became much clearer when I started ignoring full-page, dense derivations of backpropagation equations and just started writing code. Thus, this tutorial will contain very little math (I don't believe it is necessary and it can sometimes even obfuscate simple concepts). Since my background is in Computer Science and Physics, I will instead develop the topic from what I refer to as hackers's perspective. My exposition will center around code and physical intuitions instead of mathematical derivations. Basically, I will strive to present the algorithms in a way that I wish I had come across when I was starting out.
". everything became much clearer when I started writing code."
You might be eager to jump right in and learn about Neural Networks, backpropagation, how they can be applied to datasets in practice, etc. But before we get there, I'd like us to first forget about all that. Let's take a step back and understand what is really going on at the core. Lets first talk about real-valued circuits.
Update note. I suspended my work on this guide a while ago and redirected a lot of my energy to teaching CS231n (Convolutional Neural Networks) class at Stanford. The notes are on cs231.github.io and the course slides can be found here. These materials are highly related to material here, but more comprehensive and sometimes more polished.
Chapter 1: Real-valued CircuitsIn my opinion, the best way to think of Neural Networks is as real-valued circuits, where real values (instead of boolean values <0,1> ) "flow" along edges and interact in gates. However, instead of gates such as AND. OR. NOT. etc, we have binary gates such as * (multiply), + (add), max or unary gates such as exp. etc. Unlike ordinary boolean circuits, however, we will eventually also have gradients flowing on the same edges of the circuit, but in the opposite direction. But we're getting ahead of ourselves. Let's focus and start out simple.
Base Case: Single Gate in the CircuitLets first consider a single, simple circuit with one gate. Here's an example:
The circuit takes two real-valued inputs x and y and computes x * y with the * gate. Javascript version of this would very simply look something like this:
And in math form we can think of this gate as implementing the real-valued function:
$$ f(x,y) = x y $$
As with this example, all of our gates will take one or two inputs and produce a single output value.
The problem we are interested in studying looks as follows:
In this case, in what direction should we change x,y to get a number larger than -6. Note that, for example, x = -1.99 and y = 2.99 gives x * y = -5.95. which is higher than -6.0. Don't get confused by this: -5.95 is better (higher) than -6.0. It's an improvement of 0.05. even though the magnitude of -5.95 (the distance from zero) happens to be lower.
Strategy #1: Random Local SearchOkay. So wait, we have a circuit, we have some inputs and we just want to tweak them slightly to increase the output value? Why is this hard? We can easily "forward" the circuit to compute the output for any given x and y. So isn't this trivial? Why don't we tweak x and y randomly and keep track of the tweak that works best:
When I run this, I get best_x = -1.9928. best_y = 2.9901. and best_out = -5.9588. Again, -5.9588 is higher than -6.0. So, we're done, right? Not quite: This is a perfectly fine strategy for tiny problems with a few gates if you can afford the compute time, but it won't do if we want to eventually consider huge circuits with millions of inputs. It turns out that we can do much better.
Stategy #2: Numerical GradientHere's a better way. Remember again that in our setup we are given a circuit (e.g. our circuit with a single * gate) and some particular input (e.g. x = -2, y = 3 ). The gate computes the output ( -6 ) and now we'd like to tweak x and y to make the output higher.
A nice intuition for what we're about to do is as follows: Imagine taking the output value that comes out from the circuit and tugging on it in the positive direction. This positive tension will in turn translate through the gate and induce forces on the inputs x and y. Forces that tell us how x and y should change to increase the output value.
What might those forces look like in our specific example? Thinking through it, we can intuit that the force on x should also be positive, because making x slightly larger improves the circuit's output. For example, increasing x from x = -2 to x = -1 would give us output -3 - much larger than -6. On the other hand, we'd expect a negative force induced on y that pushes it to become lower (since a lower y. such as y = 2. down from the original y = 3 would make output higher: 2 x -2 = -4. again, larger than -6 ). That's the intuition to keep in mind, anyway. As we go through this, it will turn out that forces I'm describing will in fact turn out to be the derivative of the output value with respect to its inputs ( x and y ). You may have heard this term before.
The derivative can be thought of as a force on each input as we pull on the output to become higher.
So how do we exactly evaluate this force (derivative)? It turns out that there is a very simple procedure for this. We will work backwards: Instead of pulling on the circuit's output, we'll iterate over every input one by one, increase it very slightly and look at what happens to the output value. The amount the output changes in response is the derivative. Enough intuitions for now. Lets look at the mathematical definition. We can write down the derivative for our function with respect to the inputs. For example, the derivative with respect to x can be computed as:
Where \( h \) is small - it's the tweak amount. Also, if you're not very familiar with calculus it is important to note that in the left-hand side of the equation above, the horizontal line does not indicate division. The entire symbol \( \frac<\partial f(x,y)><\partial x> \) is a single thing: the derivative of the function \( f(x,y) \) with respect to \( x \). The horizontal line on the right is division. I know it's confusing but it's standard notation. Anyway, I hope it doesn't look too scary because it isn't: The circuit was giving some initial output \( f(x,y) \), and then we changed one of the inputs by a tiny amount \(h \) and read the new output \( f(x+h, y) \). Subtracting those two quantities tells us the change, and the division by \(h \) just normalizes this change by the (arbitrary) tweak amount we used. In other words it's expressing exactly what I described above and translates directly to this code:
Lets walk through x for example. We turned the knob from x to x + h and the circuit responded by giving a higher value (note again that yes, -5.9997 is higher than -6. -5.9997 > -6 ). The division by h is there to normalize the circuit's response by the (arbitrary) value of h we chose to use here. Technically, you want the value of h to be infinitesimal (the precise mathematical definition of the gradient is defined as the limit of the expression as h goes to zero), but in practice h=0.00001 or so works fine in most cases to get a good approximation. Now, we see that the derivative w.r.t. x is +3. I'm making the positive sign explicit, because it indicates that the circuit is tugging on x to become higher. The actual value, 3 can be interpreted as the force of that tug.
The derivative with respect to some input can be computed by tweaking that input by a small amount and observing the change on the output value.
By the way, we usually talk about the derivative with respect to a single input, or about a gradient with respect to all the inputs. The gradient is just made up of the derivatives of all the inputs concatenated in a vector (i.e. a list). Crucially, notice that if we let the inputs respond to the tug by following the gradient a tiny amount (i.e. we just add the derivative on top of every input), we can see that the value increases, as expected:
As expected, we changed the inputs by the gradient and the circuit now gives a slightly higher value ( -5.87 > -6.0 ). That was much simpler than trying random changes to x and y. right? A fact to appreciate here is that if you take calculus you can prove that the gradient is, in fact, the direction of the steepest increase of the function. There is no need to monkey around trying out random pertubations as done in Strategy #1. Evaluating the gradient requires just three evaluations of the forward pass of our circuit instead of hundreds, and gives the best tug you can hope for (locally) if you are interested in increasing the value of the output.
Bigger step is not always better. Let me clarify on this point a bit. It is important to note that in this very simple example, using a bigger step_size than 0.01 will always work better. For example, step_size = 1.0 gives output -1 (higer, better!), and indeed infinite step size would give infinitely good results. The crucial thing to realize is that once our circuits get much more complex (e.g. entire neural networks), the function from inputs to the output value will be more chaotic and wiggly. The gradient guarantees that if you have a very small (indeed, infinitesimally small) step size, then you will definitely get a higher number when you follow its direction, and for that infinitesimally small step size there is no other direction that would have worked better. But if you use a bigger step size (e.g. step_size = 0.01 ) all bets are off. The reason we can get away with a larger step size than infinitesimally small is that our functions are usually relatively smooth. But really, we're crossing our fingers and hoping for the best.
Hill-climbing analogy. One analogy I've heard before is that the output value of our circut is like the height of a hill, and we are blindfolded and trying to climb upwards. We can sense the steepness of the hill at our feet (the gradient), so when we shuffle our feet a bit we will go upwards. But if we took a big, overconfident step, we could have stepped right into a hole.
Great, I hope I've convinced you that the numerical gradient is indeed a very useful thing to evaluate, and that it is cheap. But. It turns out that we can do even better.
Strategy #3: Analytic GradientIn the previous section we evaluated the gradient by probing the circuit's output value, independently for every input. This procedure gives you what we call a numerical gradient. This approach, however, is still expensive because we need to compute the circuit's output as we tweak every input value independently a small amount. So the complexity of evaluating the gradient is linear in number of inputs. But in practice we will have hundreds, thousands or (for neural networks) even tens to hundreds of millions of inputs, and the circuits aren't just one multiply gate but huge expressions that can be expensive to compute. We need something better.
Luckily, there is an easier and much faster way to compute the gradient: we can use calculus to derive a direct expression for it that will be as simple to evaluate as the circuit's output value. We call this an analytic gradient and there will be no need for tweaking anything. You may have seen other people who teach Neural Networks derive the gradient in huge and, frankly, scary and confusing mathematical equations (if you're not well-versed in maths). But it's unnecessary. I've written plenty of Neural Nets code and I rarely have to do mathematical derivation longer than two lines, and 95% of the time it can be done without writing anything at all. That is because we will only ever derive the gradient for very small and simple expressions (think of it as the base case ) and then I will show you how we can compose these very simply with chain rule to evaluate the full gradient (think inductive/recursive case).
The analytic derivative requires no tweaking of the inputs. It can be derived using mathematics (calculus).
If you remember your product rules, power rules, quotient rules, etc. (see e.g. derivative rules or wiki page ), it's very easy to write down the derivitative with respect to both x and y for a small expression such as x * y. But suppose you don't remember your calculus rules. We can go back to the definition. For example, here's the expression for the derivative w.r.t x :
(Technically I'm not writing the limit as h goes to zero, forgive me math people). Okay and lets plug in our function ( \( f(x,y) = x y \) ) into the expression. Ready for the hardest piece of math of this entire article? Here we go:
That's interesting. The derivative with respect to x is just equal to y. Did you notice the coincidence in the previous section? We tweaked x to x+h and calculated x_derivative = 3.0. which exactly happens to be the value of y in that example. It turns out that wasn't a coincidence at all because that's just what the analytic gradient tells us the x derivative should be for f(x,y) = x * y. The derivative with respect to y. by the way, turns out to be x. unsurprisingly by symmetry. So there is no need for any tweaking! We invoked powerful mathematics and can now transform our derivative calculation into the following code:
To compute the gradient we went from forwarding the circuit hundreds of times (Strategy #1) to forwarding it only on order of number of times twice the number of inputs (Strategy #2), to forwarding it a single time! And it gets EVEN better, since the more expensive strategies (#1 and #2) only give an approximation of the gradient, while #3 (the fastest one by far) gives you the exact gradient. No approximations. The only downside is that you should be comfortable with some calculus 101.
Lets recap what we have learned:
In practice by the way (and we will get to this once again later), all Neural Network libraries always compute the analytic gradient, but the correctness of the implementation is verified by comparing it to the numerical gradient. That's because the numerical gradient is very easy to evaluate (but can be a bit expensive to compute), while the analytic gradient can contain bugs at times, but is usually extremely efficient to compute. As we will see, evaluating the gradient (i.e. while doing backprop. or backward pass ) will turn out to cost about as much as evaluating the forward pass .
Recursive Case: Circuits with Multiple GatesBut hold on, you say: "The analytic gradient was trivial to derive for your super-simple expression. This is useless. What do I do when the expressions are much larger? Don't the equations get huge and complex very fast?". Good question. Yes the expressions get much more complex. No, this doesn't make it much harder. As we will see, every gate will be hanging out by itself, completely unaware of any details of the huge and complex circuit that it could be part of. It will only worry about its inputs and it will compute its local derivatives as seen in the previous section, except now there will be a single extra multiplication it will have to do.
A single extra multiplication will turn a single (useless gate) into a cog in the complex machine that is an entire neural network.
I should stop hyping it up now. I hope I've piqued your interest! Lets drill down into details and get two gates involved with this next example:
x y z + q * f
The expression we are computing now is \( f(x,y,z) = (x + y) z \). Lets structure the code as follows to make the gates explicit as functions:
In the above, I am using a and b as the local variables in the gate functions so that we don't get these confused with our circuit inputs x,y,z. As before, we are interested in finding the derivatives with respect to the three inputs x,y,z. But how do we compute it now that there are multiple gates involved? First, lets pretend that the + gate is not there and that we only have two variables in the circuit: q,z and a single * gate. Note that the q is is output of the + gate. If we don't worry about x and y but only about q and z. then we are back to having only a single gate, and as far as that single * gate is concerned, we know what the (analytic) derivates are from previous section. We can write them down (except here we're replacing x,y with q,z ):
Simple enough: these are the expressions for the gradient with respect to q and z. But wait, we don't want gradient with respect to q. but with respect to the inputs: x and y. Luckily, q is computed as a function of x and y (by addition in our example). We can write down the gradient for the addition gate as well, it's even simpler:
That's right, the derivatives are just 1, regardless of the actual values of x and y. If you think about it, this makes sense because to make the output of a single addition gate higher, we expect a positive tug on both x and y. regardless of their values.
BackpropagationWe are finally ready to invoke the Chain Rule. We know how to compute the gradient of q with respect to x and y (that's a single gate case with + as the gate). And we know how to compute the gradient of our final output with respect to q. The chain rule tells us how to combine these to get the gradient of the final output with respect to x and y. which is what we're ultimately interested in. Best of all, the chain rule very simply states that the right thing to do is to simply multiply the gradients together to chain them. For example, the final derivative for x will be:
There are many symbols there so maybe this is confusing again, but it's really just two numbers being multiplied together. Here is the code:
That's it. We computed the gradient (the forces) and now we can let our inputs respond to it by a bit. Lets add the gradients on top of the inputs. The output value of the circuit better increase, up from -12!
Looks like that worked! Lets now try to interpret intuitively what just happened. The circuit wants to output higher values. The last gate saw inputs q = 3, z = -4 and computed output -12. "Pulling" upwards on this output value induced a force on both q and z. To increase the output value, the circuit "wants" z to increase, as can be seen by the positive value of the derivative( derivative_f_wrt_z = +3 ). Again, the size of this derivative can be interpreted as the magnitude of the force. On the other hand, q felt a stronger and downward force, since derivative_f_wrt_q = -4. In other words the circuit wants q to decrease, with a force of 4 .
Now we get to the second, + gate which outputs q. By default, the + gate computes its derivatives which tells us how to change x and y to make q higher. BUT! Here is the crucial point. the gradient on q was computed as negative ( derivative_f_wrt_q = -4 ), so the circuit wants q to decrease. and with a force of 4. So if the + gate wants to contribute to making the final output value larger, it needs to listen to the gradient signal coming from the top. In this particular case, it needs to apply tugs on x,y opposite of what it would normally apply, and with a force of 4. so to speak. The multiplication by -4 seen in the chain rule achieves exactly this: instead of applying a positive force of +1 on both x and y (the local derivative), the full circuit's gradient on both x and y becomes 1 x -4 = -4. This makes sense: the circuit wants both x and y to get smaller because this will make q smaller, which in turn will make f larger.
If this makes sense, you understand backpropagation.
Lets recap once again what we learned:
In the previous chapter we saw that in the case of a single gate (or a single expression), we can derive the analytic gradient using simple calculus. We interpreted the gradient as a force, or a tug on the inputs that pulls them in a direction which would make this gate's output higher.
In case of multiple gates everything stays pretty much the same way: every gate is hanging out by itself completely unaware of the circuit it is embedded in. Some inputs come in and the gate computes its output and the derivate with respect to the inputs. The only difference now is that suddenly, something can pull on this gate from above. That's the gradient of the final circuit output value with respect to the ouput this gate computed. It is the circuit asking the gate to output higher or lower numbers, and with some force. The gate simply takes this force and multiplies it to all the forces it computed for its inputs before (chain rule). This has the desired effect:
A nice picture to have in mind is that as we pull on the circuit's output value at the end, this induces pulls downward through the entire circuit, all the way down to the inputs.
Isn't it beautiful? The only difference between the case of a single gate and multiple interacting gates that compute arbitrarily complex expressions is this additional multipy operation that now happens in each gate.
Patterns in the "backward" flowLets look again at our example circuit with the numbers filled in. The first circuit shows the raw values, and the second circuit shows the gradients that flow back to the inputs as discussed. Notice that the gradient always starts off with +1 at the end to start off the chain. This is the (default) pull on the circuit to have its value increased.
(Values) -2 5 -4 + 3 * -12 (Gradients) -4 -4 3 + -4 * 1
After a while you start to notice patterns in how the gradients flow backward in the circuits. For example, the + gate always takes the gradient on top and simply passes it on to all of its inputs (notice the example with -4 simply passed on to both of the inputs of + gate). This is because its own derivative for the inputs is just +1. regardless of what the actual values of the inputs are, so in the chain rule, the gradient from above is just multiplied by 1 and stays the same. Similar intuitions apply to, for example, a max(x,y) gate. Since the gradient of max(x,y) with respect to its input is +1 for whichever one of x. y is larger and 0 for the other, this gate is during backprop effectively just a gradient "switch": it will take the gradient from above and "route" it to the input that had a higher value during the forward pass.
Numerical Gradient Check. Before we finish with this section, lets just make sure that the (analytic) gradient we computed by backprop above is correct as a sanity check. Remember that we can do this simply by computing the numerical gradient and making sure that we get [-4, -4, 3] for x,y,z. Here's the code:
and we get [-4, -4, 3]. as computed with backprop. phew. )
Example: Single NeuronIn the previous section you hopefully got the basic intuition behind backpropagation. Lets now look at an even more complicated and borderline practical example. We will consider a 2-dimensional neuron that computes the following function:
$$ f(x,y,a,b,c) = \sigma(ax + by + c) $$
In this expression, \( \sigma \) is the sigmoid function. Its best thought of as a "squashing function", because it takes the input and squashes it to be between zero and one: Very negative values are squashed towards zero and positive values get squashed towards one. For example, we have sig(-5) = 0.006, sig(0) = 0.5, sig(5) = 0.993. Sigmoid function is defined as:
$$ \sigma(x) = \frac<1><1 + e^<-x>> $$
The gradient with respect to its single input, as you can check on Wikipedia or derive yourself if you know some calculus is given by this expression:
$$ \frac<\partial \sigma(x)><\partial x> = \sigma(x) (1 - \sigma(x)) $$
For example, if the input to the sigmoid gate is x = 3. the gate will compute output f = 1.0 / (1.0 + Math.exp(-x)) = 0.95. and then the (local) gradient on its input will simply be dx = (0.95) * (1 - 0.95) = 0.0475 .
That's all we need to use this gate: we know how to take an input and forward it through the sigmoid gate, and we also have the expression for the gradient with respect to its input, so we can also backprop through it. Another thing to note is that technically, the sigmoid function is made up of an entire series of gates in a line that compute more atomic functions: an exponentiation gate, an addition gate and a division gate. Treating it so would work perfectly fine but for this example I chose to collapse all of these gates into a single gate that just computes sigmoid in one shot, because the gradient expression turns out to be simple.
Lets take this opportunity to carefully structure the associated code in a nice and modular way. First, I'd like you to note that every wire in our diagrams has two numbers associated with it:
Lets create a simple Unit structure that will store these two values on every wire. Our gates will now operate over Unit s: they will take them as inputs and create them as outputs.
In addition to Units we also need 3 gates: +. * and sig (sigmoid). Lets start out by implementing a multiply gate. I'm using Javascript here which has a funny way of simulating classes using functions. If you're not a Javascript - familiar person, all that's going on here is that I'm defining a class that has certain properties (accessed with use of this keyword), and some methods (which in Javascript are placed into the function's prototype ). Just think about these as class methods. Also keep in mind that the way we will use these eventually is that we will first forward all the gates one by one, and then backward all the gates in reverse order. Here is the implementation:
The multiply gate takes two units that each hold a value and creates a unit that stores its output. The gradient is initialized to zero. Then notice that in the backward function call we get the gradient from the output unit we produced during the forward pass (which will by now hopefully have its gradient filled in) and multiply it with the local gradient for this gate (chain rule!). This gate computes multiplication ( u0.value * u1.value ) during forward pass, so recall that the gradient w.r.t u0 is u1.value and w.r.t u1 is u0.value. Also note that we are using += to add onto the gradient in the backward function. This will allow us to possibly use the output of one gate multiple times (think of it as a wire branching out), since it turns out that the gradients from these different branches just add up when computing the final gradient with respect to the circuit output. The other two gates are defined analogously:
Note that, again, the backward function in all cases just computes the local derivative with respect to its input and then multiplies on the gradient from the unit above (i.e. chain rule). To fully specify everything lets finally write out the forward and backward flow for our 2-dimensional neuron with some example values:
And now lets compute the gradient: Simply iterate in reverse order and call the backward function! Remember that we stored the pointers to the units when we did the forward pass, so every gate has access to its inputs and also the output unit it previously produced.
Note that the first line sets the gradient at the output (very last unit) to be 1.0 to start off the gradient chain. This can be interpreted as tugging on the last gate with a force of +1. In other words, we are pulling on the entire circuit to induce the forces that will increase the output value. If we did not set this to 1, all gradients would be computed as zero due to the multiplications in the chain rule. Finally, lets make the inputs respond to the computed gradients and check that the function increased:
Success! 0.8825 is higher than the previous value, 0.8808. Finally, lets verify that we implemented the backpropagation correctly by checking the numerical gradient:
Indeed, these all give the same values as the backpropagated gradients [-0.105, 0.315, 0.105, 0.105, 0.210]. Nice!
I hope it is clear that even though we only looked at an example of a single neuron, the code I gave above generalizes in a very straight-forward way to compute gradients of arbitrary expressions (including very deep expressions #foreshadowing). All you have to do is write small gates that compute local, simple derivatives w.r.t their inputs, wire it up in a graph, do a forward pass to compute the output value and then a backward pass that chains the gradients all the way to the input.
Becoming a Backprop NinjaOver time you will become much more efficient in writing the backward pass, even for complicated circuits and all at once. Lets practice backprop a bit with a few examples. In what follows, lets not worry about Unit, Circuit classes because they obfuscate things a bit, and lets just use variables such as a,b,c,x. and refer to their gradients as da,db,dc,dx respectively. Again, we think of the variables as the "forward flow" and their gradients as "backward flow" along every wire. Our first example was the * gate:
In the code above, I'm assuming that the variable dx is given, coming from somewhere above us in the circuit while we're doing backprop (or it is +1 by default otherwise). I'm writing it out because I want to explicitly show how the gradients get chained together. Note from the equations that the * gate acts as a switcher during backward pass, for lack of better word. It remembers what its inputs were, and the gradients on each one will be the value of the other during the forward pass. And then of course we have to multiply with the gradient from above, which is the chain rule. Here's the + gate in this condensed form:
Where 1.0 is the local gradient, and the multiplication is our chain rule. What about adding three numbers.
You can see what's happening, right? If you remember the backward flow diagram, the + gate simply takes the gradient on top and routes it equally to all of its inputs (because its local gradient is always simply 1.0 for all its inputs, regardless of their actual values). So we can do it much faster:
If you don't see how the above happened, introduce a temporary variable q = a * b and then compute x = q + c to convince yourself. And here is our neuron, lets do it in two steps:
I hope this is starting to make a little more sense. Now how about this:
You can think of this as value a flowing to the * gate, but the wire gets split and becomes both inputs. This is actually simple because the backward flow of gradients always adds up. In other words nothing changes:
In fact, if you know your power rule from calculus you would also know that if you have \( f(a) = a^2 \) then \( \frac<\partial f(a)><\partial a> = 2a \), which is exactly what we get if we think of it as wire splitting up and being two inputs to a gate.
Okay now lets start to get more complex:
When more complex cases like this come up in practice, I like to split the expression into manageable chunks which are almost always composed of simpler expressions and then I chain them together with chain rule:
That wasn't too difficult! Those are the backprop equations for the entire expression, and we've done them piece by piece and backpropped to all the variables. Notice again how for every variable during forward pass we have an equivalent variable during backward pass that contains its gradient with respect to the circuit's final output. Here are a few more useful functions and their local gradients that are useful in practice:
Here's what division might look like in practice then:
Hopefully you see that we are breaking down expressions, doing the forward pass, and then for every variable (such as a ) we derive its gradient da as we go backwards, one by one, applying the simple local gradients and chaining them with gradients from above. Here's another one:
Okay this is making a very simple thing hard to read. The max function passes on the value of the input that was largest and ignores the other ones. In the backward pass then, the max gate will simply take the gradient on top and route it to the input that actually flowed through it during the forward pass. The gate acts as a simple switch based on which input had the highest value during forward pass. The other inputs will have zero gradient. That's what the === is about, since we are testing for which input was the actual max and only routing the gradient to it.
Finally, lets look at the Rectified Linear Unit non-linearity (or ReLU), which you may have heard of. It is used in Neural Networks in place of the sigmoid function. It is simply thresholding at zero:
In other words this gate simply passes the value through if it's larger than 0, or it stops the flow and sets it to zero. In the backward pass, the gate will pass on the gradient from the top if it was activated during the forawrd pass, or if the original input was below zero, it will stop the gradient flow.
I will stop at this point. I hope you got some intuition about how you can compute entire expressions (which are made up of many gates along the way) and how you can compute backprop for every one of them.
Everything we've done in this chapter comes down to this: We saw that we can feed some input through arbitrarily complex real-valued circuit, tug at the end of the circuit with some force, and backpropagation distributes that tug through the entire circuit all the way back to the inputs. If the inputs respond slightly along the final direction of their tug, the circuit will "give" a bit along the original pull direction. Maybe this is not immediately obvious, but this machinery is a powerful hammer for Machine Learning.
"Maybe this is not immediately obvious, but this machinery is a powerful hammer for Machine Learning."
Lets now put this machinery to good use.
Chapter 2: Machine LearningIn the last chapter we were concerned with real-valued circuits that computed possibly complex expressions of their inputs (the forward pass), and also we could compute the gradients of these expressions on the original inputs (backward pass). In this chapter we will see how useful this extremely simple mechanism is in Machine Learning.
Binary ClassificationAs we did before, lets start out simple. The simplest, common and yet very practical problem in Machine Learning is binary classification. A lot of very interesting and important problems can be reduced to it. The setup is as follows: We are given a dataset of N vectors and every one of them is labeled with a +1 or a -1. For example, in two dimensions our dataset could look as simple as:
Here, we have N = 6 datapoints. where every datapoint has two features ( D = 2 ). Three of the datapoints have label +1 and the other three label -1. This is a silly toy example, but in practice a +1/-1 dataset could be very useful things indeed: For example spam/no spam emails, where the vectors somehow measure various features of the content of the email, such as the number of times certain enhancement drugs are mentioned.
Goal. Our goal in binary classification is to learn a function that takes a 2-dimensional vector and predicts the label. This function is usually parameterized by a certain set of parameters, and we will want to tune the parameters of the function so that its outputs are consistent with the labeling in the provided dataset. In the end we can discard the dataset and use the learned parameters to predict labels for previously unseen vectors.
Training protocolWe will eventually build up to entire neural networks and complex expressions, but lets start out simple and train a linear classifier very similar to the single neuron we saw at the end of Chapter 1. The only difference is that we'll get rid of the sigmoid because it makes things unnecessarily complicated (I only used it as an example in Chapter 1 because sigmoid neurons are historically popular but modern Neural Networks rarely, if ever, use sigmoid non-linearities). Anyway, lets use a simple linear function:
$$ f(x, y) = ax + by + c $$
In this expression we think of x and y as the inputs (the 2D vectors) and a,b,c as the parameters of the function that we will want to learn. For example, if a = 1, b = -2, c = -1. then the function will take the first datapoint ( [1.2, 0.7] ) and output 1 * 1.2 + (-2) * 0.7 + (-1) = -1.2. Here is how the training will work:
The training scheme I described above, is commonly referred as Stochastic Gradient Descent. The interesting part I'd like to reiterate is that a,b,c,x,y are all made up of the same stuff as far as the circuit is concerned: They are inputs to the circuit and the circuit will tug on all of them in some direction. It doesn't know the difference between parameters and datapoints. However, after the backward pass is complete we ignore all tugs on the datapoints ( x,y ) and keep swapping them in and out as we iterate over examples in the dataset. On the other hand, we keep the parameters ( a,b,c ) around and keep tugging on them every time we sample a datapoint. Over time, the pulls on these parameters will tune these values in such a way that the function outputs high scores for positive examples and low scores for negative examples.
Learning a Support Vector MachineAs a concrete example, lets learn a Support Vector Machine. The SVM is a very popular linear classifier; Its functional form is exactly as I've described in previous section, \( f(x,y) = ax + by + c\). At this point, if you've seen an explanation of SVMs you're probably expecting me to define the SVM loss function and plunge into an explanation of slack variables, geometrical intuitions of large margins, kernels, duality, etc. But here, I'd like to take a different approach. Instead of definining loss functions, I would like to base the explanation on the force specification (I just made this term up by the way) of a Support Vector Machine, which I personally find much more intuitive. As we will see, talking about the force specification and the loss function are identical ways of seeing the same problem. Anyway, here it is:
Support Vector Machine "Force Specification":
Lets quickly go through a small but concrete example. Suppose we start out with a random parameter setting, say, a = 1, b = -2, c = -1. Then:
Okay there's been too much text. Lets write the SVM code and take advantage of the circuit machinery we have from Chapter 1:
That's a circuit that simply computes a*x + b*y + c and can also compute the gradient. It uses the gates code we developed in Chapter 1. Now lets write the SVM, which doesn't care about the actual circuit. It is only concerned with the values that come out of it, and it pulls on the circuit.
Now lets train the SVM with Stochastic Gradient Descent:
This code prints the following output:
We see that initially our classifier only had 33% training accuracy, but by the end all training examples are correctly classifier as the parameters a,b,c adjusted their values according to the pulls we exerted. We just trained an SVM! But please don't use this code anywhere in production :) We will see how we can make things much more efficient once we understand what is going on at the core.
Number of iterations needed. With this example data, with this example initialization, and with the setting of step size we used, it took about 300 iterations to train the SVM. In practice, this could be many more or many less depending on how hard or large the problem is, how you're initializating, normalizing your data, what step size you're using, and so on. This is just a toy demonstration, but later we will go over all the best practices for actually training these classifiers in practice. For example, it will turn out that the setting of the step size is very imporant and tricky. Small step size will make your model slow to train. Large step size will train faster, but if it is too large, it will make your classifier chaotically jump around and not converge to a good final result. We will eventually use witheld validation data to properly tune it to be just in the sweet spot for your particular data.
One thing I'd like you to appreciate is that the circuit can be arbitrary expression, not just the linear prediction function we used in this example. For example, it can be an entire neural network.
By the way, I intentionally structured the code in a modular way, but we could have trained an SVM with a much simpler code. Here is really what all of these classes and computations boil down to:
this code gives an identical result. Perhaps by now you can glance at the code and see how these equations came about.
Variable pull? A quick note to make at this point: You may have noticed that the pull is always 1,0, or -1. You could imagine doing other things, for example making this pull proportional to how bad the mistake was. This leads to a variation on the SVM that some people refer to as squared hinge loss SVM, for reasons that will later become clear. Depending on various features of your dataset, that may work better or worse. For example, if you have very bad outliers in your data, e.g. a negative data point that gets a score +100. its influence will be relatively minor on our classifier because we will only pull with force of -1 regardless of how bad the mistake was. In practice we refer to this property of a classifier as robustness to outliers.
Lets recap. We introduced the binary classification problem, where we are given N D-dimensional vectors and a label +1/-1 for each. We saw that we can combine these features with a set of parameters inside a real-valued circuit (such as a Support Vector Machine circuit in our example). Then, we can repeatedly pass our data through the circuit and each time tweak the parameters so that the circuit's output value is consistent with the provided labels. The tweaking relied, crucially, on our ability to backpropagate gradients through the circuit. In the end, the final circuit can be used to predict values for unseen instances!
Generalizing the SVM into a Neural NetworkOf interest is the fact that an SVM is just a particular type of a very simple circuit (circuit that computes score = a*x + b*y + c where a,b,c are weights and x,y are data points). This can be easily extended to more complicated functions. For example, lets write a 2-layer Neural Network that does the binary classification. The forward pass will look like this:
The specification above is a 2-layer Neural Network with 3 hidden neurons (n1, n2, n3) that uses Rectified Linear Unit (ReLU) non-linearity on each hidden neuron. As you can see, there are now several parameters involved, which means that our classifier is more complex and can represent more intricate decision boundaries than just a simple linear decision rule such as an SVM. Another way to think about it is that every one of the three hidden neurons is a linear classifier and now we're putting an extra linear classifier on top of that. Now we're starting to go deeper :). Okay, lets train this 2-layer Neural Network. The code looks very similar to the SVM example code above, we just have to change the forward pass and the backward pass:
And that's how you train a neural network. Obviously, you want to modularize your code nicely but I expended this example for you in the hope that it makes things much more concrete and simpler to understand. Later, we will look at best practices when implementing these networks and we will structure the code much more neatly in a modular and more sensible way.
But for now, I hope your takeaway is that a 2-layer Neural Net is really not such a scary thing: we write a forward pass expression, interpret the value at the end as a score, and then we pull on that value in a positive or negative direction depending on what we want that value to be for our current particular example. The parameter update after backprop will ensure that when we see this particular example in the future, the network will be more likely to give us a value we desire, not the one it gave just before the update.
A more Conventional Approach: Loss FunctionsNow that we understand the basics of how these circuits function with data, lets adopt a more conventional approach that you might see elsewhere on the internet and in other tutorials and books. You won't see people talking too much about force specifications. Instead, Machine Learning algorithms are specified in terms of loss functions (or cost functions. or objectives ).
As I develop this formalism I would also like to start to be a little more careful with how we name our variables and parameters. I'd like these equations to look similar to what you might see in a book or some other tutorial, so let me use more standard naming conventions.
Example: 2-D Support Vector MachineLets start with an example of a 2-dimensional SVM. We are given a dataset of \( N \) examples \( (x_
$$ L = [\sum_
Notice that this expression is always positive, due to the thresholding at zero in the first expression and the squaring in the regularization. The idea is that we will want this expression to be as small as possible. Before we dive into some of its subtleties let me first translate it to code:
And here is the output:
Notice how this expression works: It measures how bad our SVM classifier is. Lets step through this explicitly:
A cost function is an expression that measuress how bad your classifier is. When the training set is perfectly classified, the cost (ignoring the regularization) will be zero.
Notice that the last term in the loss is the regularization cost, which says that our model parameters should be small values. Due to this term the cost will never actually become zero (because this would mean all parameters of the model except the bias are exactly zero), but the closer we get, the better our classifier will become.
The majority of cost functions in Machine Learning consist of two parts: 1. A part that measures how well a model fits the data, and 2: Regularization, which measures some notion of how complex or likely a model is.
I hope I convinced you then, that to get a very good SVM we really want to make the cost as small as possible. Sounds familiar? We know exactly what to do: The cost function written above is our circuit. We will forward all examples through the circuit, compute the backward pass and update all parameters such that the circuit will output a smaller cost in the future. Specifically, we will compute the gradient and then update the parameters in the opposite direction of the gradient (since we want to make the cost small, not large).
"We know exactly what to do: The cost function written above is our circuit."
todo: clean up this section and flesh it out a bit.





