





 Рейтинг: 4.5/5.0 (1854 проголосовавших)
Рейтинг: 4.5/5.0 (1854 проголосовавших)Категория: Windows: Перекодировщики
Пришло мне письмо с не читаемой кириллической кодировкой и встал вопрос о декодирование этой абракадабры в читаемый набор символов. Для этих целей под Windows есть хороший софт, который не раз помогал в таких случаях – Shtirlitz IV 4.01. Но в этот раз он не выдала даже приблизительно читаемый текст.
После непродолжительного googling around был найден Универсальный декодер кириллицы .
Вкратце о возможностях:
Что сразу понравилось, так это комбобокс Выберите кодировку. в котором перечислен примерный вид исходного текста, т.е. не надо гадать какая правильная исходная и желаемая кодировка, а можно определить примерно по внешней последовательности символов.
Если в списке не было найдено примерно совпавшей кодировки можно воспользоваться Испробовать все комбинации. После нажатия кнопки OK страница перезагрузиться и в выпадающем списке можно будет просмотреть список всех возможных преобразований, среди них я нашел более-менее читаемый текст для своего случая. Правда, некоторые символы не были правильно преобразованы, но текст стал разборчивым и можно было понять смысл письма.
Есть возможность и полностью управляемого декодирования с выбором исходной кодировки, предполагаемой кодировкой и методом кодирования символов (Content-Transfer-Encoding для MIME).











Существует множество кириллических кодировок, и проблемы с неправильными кодировками в письмах или документах знакомы почти каждому. Иногда без помощи специальных программ никак не обойтись.
Размер дистрибутива: 330 кбайт
Лицензия: freeware
Очень удобный перекодировщик, который способен восстанавливать тексты в автоматическом режиме. По словам разработчика, для этого используется специальный эвристический алгоритм, основанный на принципах построения слов в русском языке. Если в автоматическом режиме восстановить текст не удалось, можно попробовать сделать это и вручную. При восстановлении поддерживаются кодировки DOS-866, WIN-1251, KOI-8, ISO 8859-5. Программа также позволяет преобразовать текст из форматов Base64, UUE, XXE, Quoted-Printable, RTF, HTML, UTF-8, а также из транслита. Интерфейс у программы очень простой и удобный. Текст, который нужно восстановить, просто-напросто всавляется в окно программы из буфера обмена. По умолчанию TCODE размещается в системной панели, и его всегда можно вызвать оттуда, если необходимо восстановить какой-либо текст.
Размер дистрибутива: 380 кбайт
Лицензия: freeware
Эта программа работает по другому принципу: здесь необходимо указать перекодируемый файл и выбрать исходную и конечную кодировки. Автоматического распознавания, к сожалению, не предусмотрено. Зато dcd работает с русскими (KOI-8, WIN-1251, ISO 8859-5, DOS-866, Macintosh), украинскими, белорусскими, болгарскими, сербскими и македонскими кодировками, а так же с Unicode. Есть возможность добавления любых других кодировок для любых языков. Поскольку при ручном выборе кодировок всегда есть опасность ошибиться и еще более запутать и без того нечитаемый текст, в программе предусмотрено создание резервной копии обрабатываемого файла.
Разработчик: Всеволод Лукьянин
Размер дистрибутива: 740 кбайт
Лицензия: freeware
"Штирлиц" - настоящая классика жанра среди перекодировщиков текста. Программа, названная по имени знаменитого разведчика, способна на многое. Она умеет расшифровывать тексты, написанные в различных русских кодировках (WIN-1251, KOI-8, DOS, ISO 8859-5, MAC и др.), в транслите, в форматах Quoted Printable, UTF-7, UTF-8, RTF, HTML, закодированные с помощью UUE, XXE, 7-битной кодировки BASE64, binhex, а также тексты, подвергшиеся смешанному перекодированию.
По умолчанию программа настроена на автоматическое распознавание и преобразование текста, а это значит, что малопонятную абракадабру стоит лишь вставить в окно программы и она моментально будет преобразована. "Штирлиц" умеет следить и за буфером обмена, и текст, скопированный туда, автоматически оказывается в окне перекодировщика.
Для расшифровки текста в программе "Штирлиц" предусмотрены несколько режимов. Например, режим Turbo ускоряет проверку текста, однако если текст неоднороден (используется смешанная кодировка), этот режим может не принести результатов. При режиме Fragments программа вначале выделяет в тексте фрагменты в разных кодировках. Декодирование можно также ограничить такими параметрами, как максимальная глубина вложений (смешанных кодировок), максимальное время в секундах, за которое программа должна найти путь декодирования и степень читаемости текста, в которой он может считаться раскодированным.
Помимо работы с кодировками, "Штирлиц" обладает еще и некоторыми возможностями по форматированию текста.
К сожалению, сайт программы уже продолжительное время не работает, однако ее всегда можно найти на одном из многочисленных софтверных каталогов в интернете.
UTF-8 (Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-битный») — одна из общепринятых и стандартизированных кодировок текста, которая позволяет хранить символы в Unicode. Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D. Кодировка нашла широкое применение в UNIX-подобных операционных системах и веб-пространстве. В качестве BOM использует последовательность байт EF16, BB16, BF16 (что является трёхбайтовой реализацией символа FEFF16). Одним из преимуществ является совместимость с ASCII — любые их 7-битные символы отображаются как есть, а остальные выдают пользователю мусор (шум). Поэтому в случае, если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объём текста, UTF-8 даёт выигрыш по объёму в сравнении с UTF-16.
Windows-1251 (синоним CP1251) — является стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8?битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только знак - ударение); она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского, македонского и болгарского.
Универсальный онлайн декодер (переводчик кодировок)Такой переводчик (сервис или программное обеспечение) еще называют как дешифратор. если Вам приходится работать с разными кодировками текста или возникли проблемы с кодировкой страниц в PHP (отображение в виде странной комбинации загадочных символов - "кракозябры"). Функциональный и универсальный сервис в режиме онлайн, автоматически поможет определить кодировку, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую и перевести текст из одной кодировки в другую. То есть универсальный декодер поможет перевести текст (предположим, что на кириллице) в другие международные форматы.
Чтобы воспользоваться переводчиком кодировок текста в режиме онлайн, просто перейдите по ссылке [ДЕКОДЕР]
Данный декодер универсален, хотите закодировать текст для PHP или HTML страниц, а может быть в Java? Все проблемы кодировок решаются раскодировкой (перекодировкой) путем декодера, но способ кодирования зависит от формата документа в котором тот был закодирован и для этого необходимо сменить формат самого документа, а не изобретать новые способы интерпритации. В случае с серверами используйте их конфигурацию — онлайн переводчик кодировок поможет узнать какая именно кодировка используется в вашем случае — вставьте скопированные символы в окно декодера.
Выберите кодировку
Введите строку в одно из полей и нажмите соответствующую кнопку
Строка в нормальном виде
Строка в закодированном виде
Кодирование символов, имеющих специальное назначение в html
Кодирование символов, для которых есть мнемонические имена в html
Кодирование всех символов
Исключая диапазон latin1
Побайтное представление (дамп)
кодирование в base64
Основные возможности кодировщикаТеоретические основы кодирования и комментарии к работе программы читайте в статье о принципах работы html кодировщика. Для просмотра начального диапазона символов Unicode (первые 64К) можно воспользоваться динамической таблицей символов блоков Unicode. Для изучения основ Unicode воспользуйтесь официальной документацией на Unicode (на английском).
Друзья, вероятно Вам когда-либо приходилось получать на почтовый ящик письма, заголовок которых или сам текст представлял собой набор кракозябр. Я раньше обычно удалял такие письма, т.к. не знал, что с ними делать и как их прочитать.
Однако как-то раз мне пришло очень важно письмо, которое я долго ждал, но оно тоже состояло из кракозябр вместо букв. Смысл его мне надо было выяснить во что бы то не стало, поэтому я начал искать, как можно расшифровать текст в таких случаях.
Оказывается подобные проблемы возникают, когда письмо пишется без указания кодировки, а почтовый клиент, пытаясь сам подобрать нужную кодировку, часто делает это неправильно. Прочесть письмо в таком случае можно несколькими способами:
В Интернет я нашел ряд декодеров, однако почти все они со своей задачей справились плохо или совсем не справились. Лишь один из них сделал все быстро, качественно, и им я пользуюсь с тех пор всегда.
Декодер Лебедева – один из онлайн инструментов на сайте самой крупной и известной дизайн-студии в России. Он поддерживает более двух десятков видов кодировок, как распространенных, так и довольно экзотичных: UTF-8, KOI8, ASCII, CP-1251, Shift_JIS, Base64, HTML-entities и др.
Декодер Лебедева имеет два режима работы, которые называются: «просто» и «сложно». Простой режим представлен обычным окошком, куда вы загоняете свой текст из кракозябр, и кнопкой «расшифровать».
В сложном режиме Вы можете вручную выбирать кодировки как исходного так и полученного текста, хотя честно говоря, не знаю, когда это может пригодиться. Лично мне всегда хватало простого режима работы — декодер Лебедева справлялся во всех случаях на УРА.
Помимо того, что вместо кракозябр Вы получите текст, дешифратор Лебедева укажет еще, в какой именно кодировке было написано письмо.
Заранее предвижу замечания некоторых моих постоянных читателей о том, что подобные сервисы попросту крадут Вашу личную информацию в своих корыстных целях. Но на это у меня есть ответ в духе Артемия Лебедева: «не хотите – не пользуйтесь». Этот продукт лишь для тех, кто не страдает манией преследования и тотальной слежки со стороны Большого брата. А то, что в этом году данный декодер отпраздновал уже 15 лет своей жизни, кое о чем да говорит…
Друзья, декодер Лебедева уже не один раз выручал меня, поэтому я смело рекомендую его Вам. Когда в следующий раз Вы получите письмо непонятного содержания, состоящее из кракозябр вместо букв, вспомните об этой статье, и Вы сможете быстро решить эту проблему.
Оцените статью, пожалуйста:
О превосходстве кодировки utf-8 над windows-1251 я уже слышал давно, но не предавал этому значения, так как проблем с отображением текста web страниц ни когда не возникало.
Вернее, проблемы-то были, но они всегда решались одним из трёх верных способов, о которых и пойдёт речь.
Кодировка utf-8UTF-8 (от англ. Unicode Transformation Format — формат преобразования Юникода) — в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб пространстве. В Unicode насчитывается свыше 100 000 символов.
Кодировка Windows-1251 (синоним CP1251)Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8?битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографии для обычного текста (отсутствует только значок ударения); она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского. Общее количество символов порядка - 256 шт.
Отличие кодировокГлавное отличие кодировок - это количество символов и здесь явно лидирует UTF-8.
Наверно, единственный плюс кодировки windows-1251 – она однобайтовая, следовательно, занимает меньший объём. Но сегодня, когда дисковое пространство измеряется гига-тера-байтами, вряд ли, кто-то будет считать байты.
И еще одно обстоятельство, которое меня окончательно убедило использовать кодировку UTF-8 – это технология AJAX, которая не поддерживает windows-1251.
Так, что если Вы еще не определились, какую кодировку использовать для Ваших web страниц, то советую остановиться на Юникоде (UTF-8), что бы в дальнейшем не пришлось переводить весь сайт с кодировки windows-1251 на utf-8.
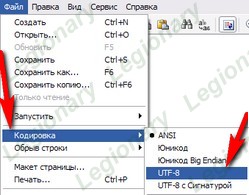
Перекодировка файлов в utf-8 в три шагаДля того, что бы сменить кодировку страницы, необходимо открыть файл в Adobe Dreamweaver и в окне «свойства страницы» установить нужную кодировку и нажать OK.
Ни каких галочек BOM ставить не надо.
Многие программы Windows (включая Блокнот) добавляют байты 0xEF, 0xBB, 0xBF в начале любого документа,
сохраняемого как UTF-8. Это метка порядка байтов Юникода (англ. Byte Order Mark, BOM), также её часто
называют сигнатурой (соответственно, UTF-8 и UTF-8 with Signature). По наличию сигнатуры программы могут
автоматически определить, является ли файл закодированным в UTF-8, однако файлы с такой сигнатурой
могут некорректно обрабатываться старыми программами, в частности xml-анализаторами.
Можно так же использовать текстовый редактор NotePad++,
но при этом не забывайте изменять запись в <head>:
Dreamweaver это делает автоматически.
А что же делать, если вы наклепали сотню другую html - файлов, прежде чем узнали о превосходстве кодировки UTF-8?
В ручную с помощью вышеупомянутых программ перекодировать все файлы отнимет уйму времени. Да и выполнять однообразную работу по смене кодировки в html- файлах вряд ли кому-то доставит удовольствие.
Думаю, с этой проблемой сталкиваются многие начинающие web мастера (скажу честно, я не исключение). Поэтому и выкладываю решение данной задачи.
Затем отправляем этот файл на сервер в ту папку, где находятся HTML страницы в кодировке Windows-1251
Теперь остаётся только открыть файл "recode.php" в любом удобном для вас браузере и нажать кнопку.
Через секунду или две все файлы с разрешением .html и .htm поменяют кодировку с windows-1251 на utf-8.
А в конфигурационный файл ".htaccess" пропишется кодировка по умолчанию UTF-8.
Хочу заметить, что это всё возможно только при поддержке сервером технологии PHP.
Для настройки сервера необходимо создать (если файла нет) в любом текстовом редакторе файл с именем .htaccess (с точкой в начале).
.htaccess (от. англ. hypertext access) — файл дополнительной конфигурации веб-сервера Apache,
а также подобных ему серверов. Позволяет задавать большое количество дополнительных
параметров и разрешений для работы веб-сервера в отдельных каталогах (папках), таких
как управляемый доступ к каталогам, переназначение типов файлов и т.д. без изменения
главного конфигурационного файла.
Для отображения правильного, читабельного текста в таблицах базы данных. а так же при выводе данных на веб страницу необходимо полное соответствие кодировок.
Решается это внесением дополнительной строки перед закрывающемся тегом ?> в PHP код подключения к базе данных:
Если после выполнения этих шагов по решению проблем с кодировкой текста на Ваших страницах не исчезнут кракозябры, то не стесняясь, обращайтесь в техподдержку хостера .
Видеокурс "Вёрстка сайта с нуля " - это уникальная информация по созданию страниц любой сложности.
Пройдя данный курс, Вы сможете не только верстать страницы с любым по сложности дизайном, но и выводить на чистую воду недобросовестных верстальщиков, которых в Рунете около 95% (. ). Поэтому данную информацию надо знать всем: кто создаёт сам и кто заказывает их на стороне .
Также вёрстка страниц - это очень прибыльное дело. Заработок верстальщиков составляет от 100 рублей в час у новичков до 1500 рублей в час уже у профи. которым Вы станете после просмотра курса и практики.
Также в Видеокурсе "Вёрстка сайта с нуля " рассказывается о том, как искать заказчиков, где их искать, как им писать в первый раз. Всё это я подробно рассказываю в курсе, а также даю уже готовый вариант первого обращения к заказчику. С таким обращением вероятность того, что заказчик к Вам обратится, близка к 100%. А учитывая, что Вы будете профессионалом, то этот заказчик превратится в постоянного!
Весь курс соткан из практических примеров реальной вёрстки. А также почти к каждому уроку идут упражнения для закрепления материала. поэтому в отличном результате можете быть уверены!
Как изменить кодировку текста документа в программе Microsoft Word?
Автор: Человек Гриф
 Случалось такое, что отправляли своему другу документ созданный в Microsoft Word, а друг прочесть не мог, на экране отображались мало понятные символы. Это проблема кодировки.
Случалось такое, что отправляли своему другу документ созданный в Microsoft Word, а друг прочесть не мог, на экране отображались мало понятные символы. Это проблема кодировки.
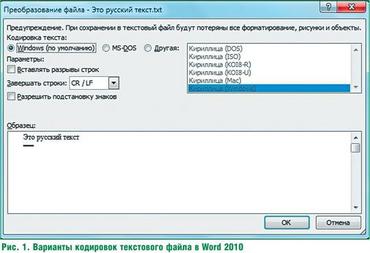
Кодировка текстового документа говорит вашему компьютеру, как надо преобразовать информацию для правильного отображения символов на мониторе. Многие языки применяют уникальные знаки, и эти знаки правильно отобразятся только в том случае, если документ закодирован именно под этот язык. В программе Microsoft Word вы сможете выбрать нужную кодировку документа, когда сохраняете его в качестве текстового файла.
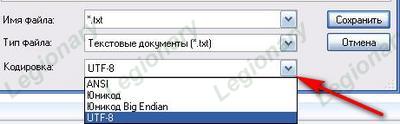
1. Жмем вкладку «Файл» в выпавшем меню в левом верхнем углу окошка программы Microsoft Word, а потом выбераем «Сохранить как».
2. Жмем в выпавшем меню «Тип файла» и выбераем «Обычный текст».
3. Жмем кнопочку «Сохранить». Появляется окно «Преобразование файла».